At the Compass AI & Data Summit in Budapest, Tasman Analytics CEO Thomas in’t Veld fielded 12 questions from data leaders navigating modern data challenges. This Q&A session covered practical strategies for building effective data teams and infrastructure.
Key Takeaways:
- Build vs Buy: Default to buying tools unless solving genuinely unique problems—avoid spending months building commodity functionality like text-to-SQL engines
- Data Modeling First: Start with half-day stakeholder workshops using paper exercises to align on business definitions before choosing technology
- Security Through Architecture: Use presentation layers to prevent raw data access and PII exposure—the data model is your first line of defense
- Dashboards Are Starting Points: Data teams succeed by sitting with stakeholders to understand decision-making needs, not by delivering polished dashboards in isolation
- Event Data Pragmatism: Don’t be afraid to discard outdated, untrusted event data—year-old data rarely impacts forward-looking business decisions
- SQL as Universal Language: Your data warehouse and modeling choices matter most; well-modeled data works with any BI or AI tool
This session provided actionable guidance for European scale-ups tackling data transformation, security requirements, and stakeholder adoption challenges.
Table of Contents
- How Agile Fits in AI & Data Environments
- Build vs Buy: When to Develop In-House vs Purchase Tools
- Cybersecurity Best Practices for Modern Data Stacks
- Why Dashboards Shouldn’t Be Endpoints
- GDPR and Smart Data Retention Strategy
- Universal Data Modeling Approaches That Scale
- Semantic Layer vs Presentation Layer: Understanding the Difference
- Getting Leadership to Actually Use Your Dashboards
- Harmonizing Data Warehouses and BI Tools (Databricks, Snowflake, Power BI)
- Choosing the Right Database for Analytics
- Understanding Data Source Relationships and Lineage
- Auditing and Fixing Inconsistent Event Tracking
Question 1: How does ‘agile’ fit within an AI and data-first environment?
‘Agile’ in data teams means mapping roadmaps to user needs through sprints and iterative delivery. But the dogmatic ‘agile’ debate from five years ago has faded. Do what works for your team and avoid mixing ‘agile’ with rigid six-month pre-planning.
For us at Tasman, ‘agile’ means we know what the roadmap looks like, we know what the users need in terms of functionality—whether it’s from reporting, data engineering or modeling. We can map out the requirements to what’s technically necessary and run this in a cost-efficient way. For us that means sprints, story points, and boards.
If you’re an internal team, you might not need it. You might be able to run longer projects that are really pre-planned because there’s not much uncertainty anymore. Or you can run more day-to-day style approaches.
“The worst thing you could do is try to do ‘agile’ while still trying to pre-plan everything six months ahead of time. That doesn’t work.”
I don’t think the level of discussion on ‘agile’ is as dogmatic as it was four or five years ago. Do whatever works for you. But that’s the only certainty I have about all of that. All the rest is up to you.
Read more: Why analytics engineer should think like product managers?
Question 2: What are your suggestions regarding whether to develop something in-house, use open source free tools, or pay for solutions?
Default to buying unless you’re solving genuinely unique problems. Always build your CI/CD layer and testing framework, but buy commodity tools like text-to-SQL engines.
Different for enterprise versus startups and scale-ups. For startups and scale-ups I’d say never really build it yourself unless you’re absolutely sure that this is something that only you can build.
I see too many teams spend six months on building a text-to-SQL engine, for instance, where I know you could just get those off the shelf and do a better job, provide better product value, and deliver better customer support than anything you could do yourself.
Build the CI/CD layer yourself, because you want to control that quite extensively. Build your tests yourself, don’t rely on off-the-shelf solutions. But that’s a slightly different layer of abstraction.
If you’re an enterprise, you know your requirements can be very different. You might not be able to run the same SaaS tools that startups and scale-ups use. That’s quite a different scenario. So there you might not have any other option than to build it yourself, particularly if your volumes of events, for instance, are very high. But luckily the days that people were home-coding their own event data are long past – there are excellent solutions for all those things out there. The big argument should be an exception to build it yourself rather than a default.
Question 3: What do you think about cybersecurity considerations?
The biggest risk is querying raw data directly. Use well-designed data models and presentation layers to prevent PII exposure. Your data model is your first line of defense.

When we do projects for clients, we never work in our systems, we always work within their systems. Basic cybersecurity isn’t a solved problem, but Snowflake and Databricks have excellent access permission structures that allow you to really lock down systems in ways that you couldn’t do five, six years ago. And it’s probably the biggest advantage compared to new tools like MotherDuck and others.
When it comes to security in the different tools, CI/CD is quite an important part here because you can test for security, for particular access drift or similar. Most of these tools that we use are configurable with code all the way down, all the way from ingestion to reporting. It’s the same with access control. You can control access all the way down as well. You can say there are reports that only C-level execs can access, and that works together with the roles-based access control that you have in Snowflake to ensure that only they can query the data. So all those cybersecurity best practices apply.
The main risk is querying raw data. One of the reasons that the data model exists is to remove raw data access as much as possible from downstream consumption patterns.
It’s another reason why you do not want your AI implementation to access or query your raw data. Because at that point you do open yourself up for exposing PII where you don’t want to. The biggest cybersecurity risk comes with AI and the cyber actors – the bad actors can also make steps more quickly than before.
We think that a really good, well-designed data model that can answer any type of business question, as long as the business doesn’t change, is the key philosophical principle to ensure that you’ve got good security all the way through. You should be able to filter out any of the dangerous information or PII and only surface in your reporting that which is safe, relevant and business actionable – protecting against SQL injection and similar attacks.
Question 4: What does it mean that we should we avoid dashboards as endpoints?
Dashboards should start conversations, not end them. If your data team only delivers dashboards without sitting with decision-makers, you won’t get very far. The endpoint is insight-driven decisions, not polished visualizations.
What I mean is not that dashboards are bad – what I mean is a dashboard is where discussion with your team starts. If as a data team you just consider your job to be delivering dashboards to your decision makers, I’m not sure you’re going to get very far at this point. You’ve got to sit next to them and try to understand what it is about the decisions they’re making and help guide them.
The start of the discussion should be the dashboard, but the endpoint should be sitting next to your stakeholders and helping them visualize customer acquisition costs against customer lifetime value. “Oh, you want to split up by geo? Okay, let’s do this as well,” and so on.
Read more: Are You Manufacturing Insights or Just Collecting Data?
Question 5: What about GDPR and data retention?
GDPR has positively changed data retention culture, and now you can only keep personal data with genuine business reasons. A well-designed data model means you can delete raw data while maintaining business intelligence. Data protection should be owned by the data engineering team.
I think people are much more mature around figuring out why we need to keep something rather than just keeping everything. There are data points that you just need to gather over a 10-50 year time horizon, particularly if it’s about financial transactions or anything that’s really core business logic. But if you do your job well on the data model, you actually can forget about the raw data, or you can at least start deleting the parts of the raw data that you just don’t need anymore. So data protection is a core part and in my view it should be owned by the data engineering team.
Question 6: Do you have suggestions for a general data model that fits all sizes?
That’s the main question in many ways. Model it as a paper exercise first. We do that. It’s half a day. Get your stakeholders in the same room and say, “Hey folks, we’re going to define your central logic and we’re going to have disagreements about definitions.”
Always assume the stakeholder does not know the data as well as you do.
So build the first version that you can build understanding their requirements, understanding what’s possible with data, and then have the conversation about what it is that they need and how to iterate from there.
As for the specific modeling approach – sometimes it’s one big table, sometimes it’s fact and dimension tables, sometimes it’s a very complex snowflake-style star schema. Do whatever works best for you. Different tools have different preferences as well. A tool like Sigma or Power BI is much more comfortable with one big table than a tool like Omni, which is more comfortable with dimensional models. So it really depends on your consumption patterns.
The main layer should allow for rapid scale and be dynamic. There’s a lot of good information online. Check out our Photoroom success story as an example of what we’ve built for a subscription business. Get a V1 in place. Also don’t forget that the current set of modern data modeling tools are pretty good at servicing these types of relationships as well. Have conversations, get inspiration for a V1 by asking what are typical event definitions in a mobile subscription startup or an e-commerce company, and then let them lead you from there.
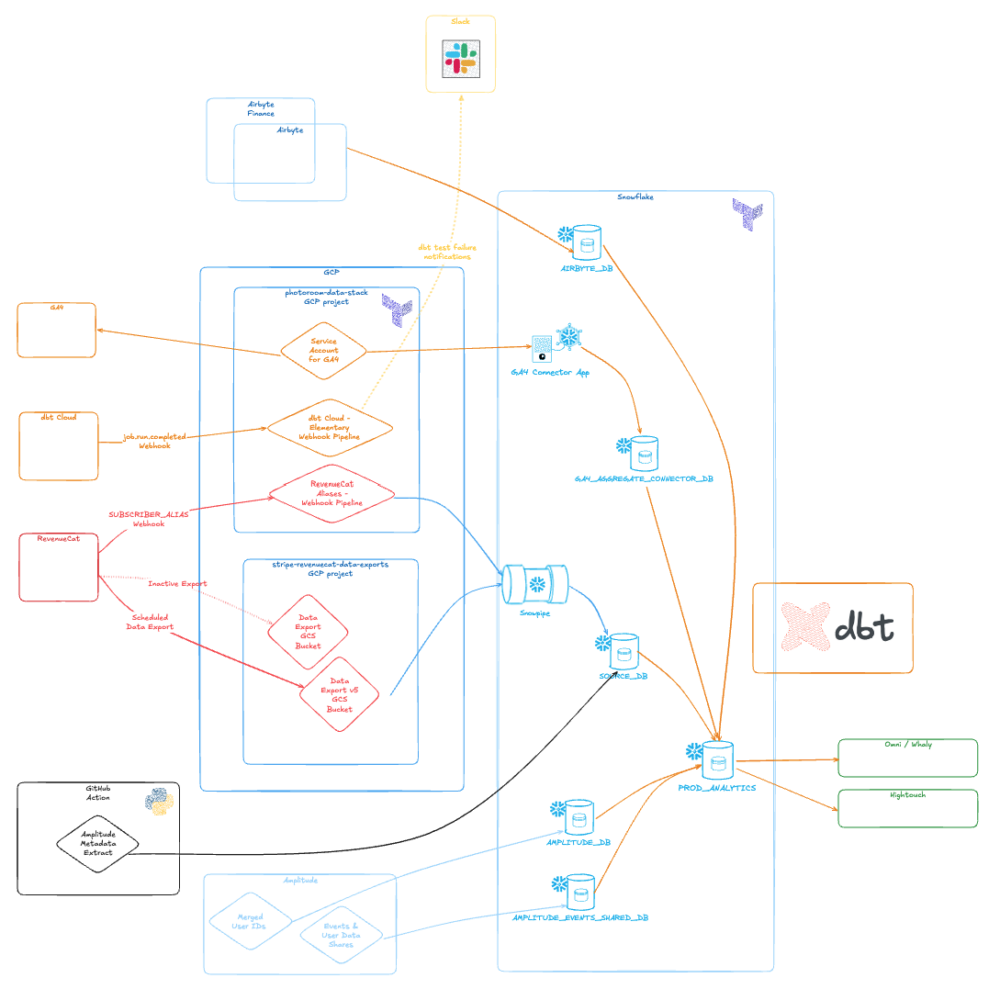
Example of Photoroom’s data stack
Question 7: Is the domain and presentation layer in a data warehouse a requirement or alternative to the semantic layer?
It’s a requirement, but there are semantic layers that can work with raw data as well – it just depends on how good you want to make it. For me, the presentation layer is about servicing a single source of truth data. The semantic layer is about telling you how you can aggregate the data.
So the semantic layer is a set of rules. The presentation layer is a set of tables with data in it. That’s the difference.
You can build semantic layers on top of raw data, but I think you’ll struggle to scale this or at least to make it perform over 6, 12, 18 months, particularly in a scale-up environment where your questions will change.
Read more: Why Agentic Analytics Fails Without Semantics
Question 8: What can be done when leadership isn’t using the dashboards we create?
That’s the whole problem. You spend two months on a great dashboard and then your CMO isn’t using it. They will have a particular set of certain requirements that you have to build for.
Always assume the stakeholder does not know the data as well as you do. So build the first version that you can build understanding their requirements, understanding what’s possible with data, and then have the conversation about what it is that they need and how to iterate from there.
If that still gets you into trouble or if it still means that they’re not using the dashboard two months down the line, then maybe they’re not as data-driven as they want to be, which is not your problem, it’s their problem. But the advice I give is: sit next to them.
Question 9: Any insights on harmonising between Databricks and Power BI Copilot? What are the best steps?
Honestly, it’s a great time at this point to build data stacks because while we see some consolidation into tools like Databricks and Snowflake, there are still so many different choices out there for every single layer in your data stack. I was thinking at one point to just give you an overview of the different choices you have, but there are just too many. It’s part of the problem as well, as I described earlier. You need to be very opinionated about all of this to be convinced that one tool is obviously better than the other tool, but it is the best possible time to build all of this from scratch for sure.
SQL is a common language, meaning that if you build your data stack well it can be consumed by any AI tool, any downstream business intelligence consumption or reporting tool, whatever it is. So you don’t really need to make a choice upfront.
The only choice you need to make upfront is your data warehouse and how you’re going to model your data. So do that wisely as suggested.
When it comes to relational data storage, they’re pretty equivalent when it comes to functionality, whether you use Databricks, Snowflake, or others – though they do lock you in a little bit.
Question 10: A non-data person asks – what is your best recommendation for a database and how to store data?
Use a cloud data warehouse for sure. Don’t use MySQL. We like cloud data warehouses. For relational data storage, they’re pretty equivalent when it comes to functionality, whether you use Databricks, Snowflake, or similar tools.
Question 11: How do you make sense of relationship logic when you don’t really get support to understand the sources of your data?
That’s a problem. Keep receipts. Keep receipts, copies of emails you sent out to your stakeholders, or get invited to the sessions which you can point to and say, “You had a chance to define the logic here.”
This is probably where I’d say there’s a lot of good information online. There’s work we did that you can reference. We’ve got information on our website about subscription businesses and event tracking that we’ve built. So have a look at that and see if it inspires you to at least get a V1 in place.
See also: Success Stories
Question 12: What is the best approach to audit event tracking that is inconsistent over time and difficult to maintain?
I think people overestimate the importance of old event data. One thing about event data is that once it’s generated, it’s done. You can’t go back and regenerate the event or redefine the event. It’s there.
If you don’t trust your events from a year ago, just discard them. I also think – because today data is meant to inform forward-looking decisions by your business – it turns out that event data from a year ago is just not as relevant as people think in current business decision-making. So don’t be afraid to cut your losses, burn it with petrol and fire, and just move on from there.
If you do need to audit and repair legacy applications where the event tracking is inconsistent, yes you need to do the data model work and this is a very expensive migration job which no one really likes to do.
I think it’s a difficult thing to get around particularly if it hasn’t been maintained well. You know what they say – the best time to fix it was a year ago, the second best time is today. So if you have a messy event architecture, please come talk to us at that point and we can help you make it better for the future.
Read more: Event Tracking Pitfalls & Principles
About the Speaker

Thomas in’t Veld is CEO and Founder of Tasman Analytics. With 15+ years in data engineering and analytics, Thomas specializes in helping scale-ups build data foundations that enable growth without creating technical debt. He regularly speaks at European data conferences on topics ranging from data modeling to stakeholder engagement to building anti-fragile data architectures.
Connect with Thomas: LinkedIn
Topics Covered: Data Strategy, Data Modeling, Cybersecurity, GDPR, Agile Methodology, Build vs Buy, Data Warehousing, Stakeholder Engagement, BI Tools, Event Tracking, Semantic Layers, Data Governance
Event: Compass AI & Data Summit 2025, Amsterdam, Netherlands