If you’ve done a good job as a data team, your data catalogue knows that dim_users.is_active is a boolean. But it has no idea that this dimension changed three times last year. And that a data analyst put it in in 2023 to do a quick board report but didn’t really align the definition with the product team’s Amplitude setup.
Nobody’s told the catalogue any of this because — well, nobody tells the catalogue anything.
The problem isn’t bad data. It’s lost context. And it’s about to get dramatically worse as agents start executing without it.
The context layer: what the metrics layer was supposed to be
Probably the best verbalisation is in an August 2025 essay, articulating this gap as ‘The Context Layer’ — Benn Stancil (founder at Mode Analytics, for those of you who remember) traced the arc of a familiar failure. The metrics layer — that universal repository for metric definitions sitting between the warehouse and BI tools — was supposed to solve consistency. A number of companies built products around the idea. Most pivoted or got acquired (remember how dbt had to buy in a better solution? yeah). The concept couldn’t survive without a BI tool attached to it, and nobody wanted to buy metric definitions on their own.
Then AI changed the landscape. Agents translating natural language into SQL need more than column names and join paths. They need to know that ‘revenue’ means something different in the marketing dashboard than it does in the finance pack. Semantics only get you so far. They need to know that the customer segmentation model was rebuilt in January and the old cohort definitions no longer apply. They need, in short, everything an experienced analyst carries around in their head.
I think Stancil’s observation is that analysts are the context layer. They learn facts directly, develop pattern-matching skills, and build mental models no tool currently captures. The question is whether we can encode even a fraction of that into infrastructure and governance — and what happens when we can’t. Always remember that we are still solving GDPR issues after ten years of heavy investment.

Three types of context debt your team is probably carrying
Context isn’t a feature you bolt on. It’s a fundamentally different type of knowledge, and I don’t think the data industry has good primitives for it yet.
We find it useful to think about three types of debt accumulating at the same time. Definitional debt is the most visible: metric definitions scattered across dbt models, Looker explores, and somebody’s Notion page — sometimes contradicting each other. Semantic layers partially address this one. Decisional debt is harder to spot: the undocumented reasoning behind data model choices, filter decisions, and business rules. Why did we exclude returns from that revenue metric? Who decided trial users don’t count in the activation funnel? If the person who made that call has left, you’re guessing. Temporal debt is the most insidious: how and why definitions changed over time. Git tracks the what; nobody tracks the narrative why.
These compound in ways we’ve seen play out across dozens of client engagements. Every departure takes institutional knowledge with it — the analyst who built the attribution model left six months ago and their Slack DMs went with them. Every tool migration resets context — move from Amplitude to a warehouse-first approach and the reasoning behind event definitions doesn’t transfer. Every AI-generated model bypasses human understanding entirely.
That last point deserves attention. Margaret-Anne Storey formalised it recently in a piece on how generative and agentic AI shift concern from technical debt to cognitive debt. Her definition is precise: cognitive debt is the accumulated gap between a system’s evolving structure and the team’s shared understanding of how and why that system works. Technical debt lives in the code; cognitive debt lives in your team’s heads. I think this framing matters because AI makes the problem both more urgent — agents need context to function — and harder to solve — AI-generated code bypasses the human understanding that creates context in the first place.
We see this at Tasman constantly. A team inherits hundreds of dbt models with sparse documentation. New analysts spend weeks reverse-engineering business logic that took months to develop, and now they’re being asked to plug AI agents into the same stack. Ugh, that’s a rough place to be.
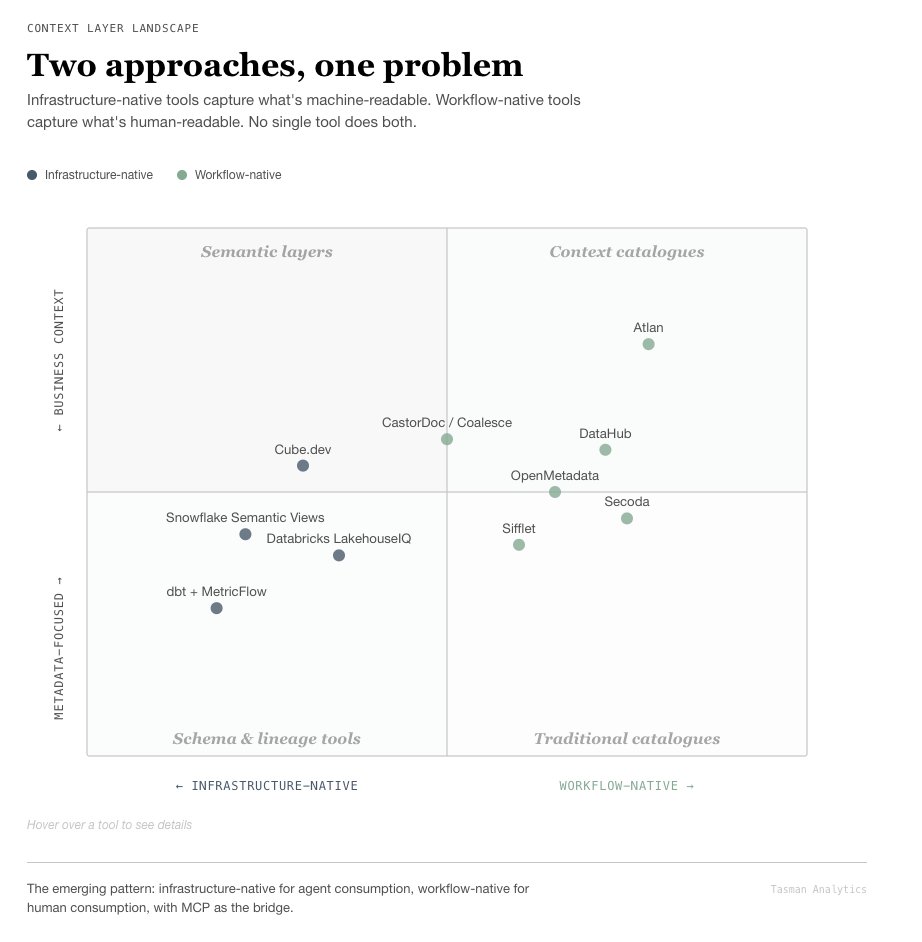
Two fundamentally different approaches to solving it
The market is converging on this problem from opposite directions. The distinction matters because it determines what you’re actually buying.
Infrastructure-as-code: structured, precise, and machine-readable
These platforms start from the data stack and work outward. They capture context as structured metadata, co-located with code.
dbt’s meta fields, documentation blocks, and MetricFlow form the zero-cost foundation. Meta fields accept arbitrary key-value pairs on every model and column. MetricFlow — open-sourced under Apache 2.0 in June 2025 — gives agents deterministic metric queries. The dbt MCP Server exposes it all to AI agents via the Model Context Protocol. If you’re already using dbt, this is where I’d start — it costs nothing and the structured context for conversational analytics docs lay out the architecture clearly.
Snowflake Semantic Views add native schema objects with verified queries, custom instructions, and named filters. Practical if you’re already on Snowflake and don’t want another tool in the stack. Cube.dev takes a different angle, storing semantic definitions as embeddings and injecting relevant context into the LLM prompt at query time. They report near-perfect accuracy when queries pass through the semantic layer versus 80%+ failure rates from direct LLM-to-SQL. Typedef’s comparison of MetricFlow, Snowflake, and Databricks is worth reading if you’re evaluating.
The strength here is precision — everything is version-controlled and machine-readable. The weakness: these systems only capture what someone explicitly encodes. They don’t capture the Slack thread where the CFO agreed to change the revenue definition, or the meeting where the team decided to exclude certain product lines from the churn metric. In my experience, that’s where most of the important context actually lives.
Workflow-native platforms: closer to how decisions actually happen
These start from how teams communicate and decide, then try to make that knowledge findable and — ideally — machine-readable.
Atlan and its context graphs capture operational metadata, decision traces, and temporal context — distinct from knowledge graphs by including the ‘why’ alongside the ‘what’. Enterprise pricing (~$30K+/year) reflects the ambition. DataHub (backed by Acryl Data) launched Context Documents in January 2025 — the first explicit product feature for organisational knowledge in a data catalogue — and hosted the CONTEXT Summit with 1,500+ data leaders from Apple, Netflix, and Block. OpenMetadata offers an open-source alternative with a Knowledge Center for wiki-style business context. Secoda targets lean teams with AI-native search at ~$800/month.
One signal I’d pay attention to: CastorDoc was acquired by Coalesce in March 2025. Its ‘Sync Back’ feature pushes documentation from the catalogue back into dbt and Snowflake — context embedded in the transformation workflow rather than bolted alongside it. That direction feels right to me.
The strength of workflow-native platforms is that they capture the messy, narrative context that infrastructure-as-code misses. The weakness is adoption. If the team doesn’t use it, you’ve purchased a fancy empty wiki. We’ve seen this happen more often than we’d like.
So what actually works?
No single tool solves cognitive debt today. The best catalogues capture what data exists and how it flows. Capturing why still requires human discipline — though better tooling lowers the friction considerably.
The pattern we see working across clients: infrastructure-native for agent consumption, workflow-native for human consumption, with the Model Context Protocol emerging as the bridge layer between them. AtScale’s take on why agents need a semantic layer explains the architecture if you want to go deeper.
How to build your context layer (two practical paths)
Two paths depending on where you are. Both share the same principle: context is infrastructure, not documentation.
Path A: Building a data stack from scratch
You have the rare advantage of building context capture into the foundation. Don’t waste it.
Weeks 1–2: Set up dbt with context-first defaults. Rich description blocks on every model and column from day one — treat undocumented models as broken models. Use meta fields for business owner, rule summaries, known caveats, and definition status (draft / agreed / deprecated). Implement dbt-checkpoint pre-commit hooks to block commits without descriptions (setup guide). I keep saying this to clients: this single action has the highest return of anything on the list.
Weeks 2–4: Establish the decision trail. Create a /decisions/ folder in your dbt repo for lightweight Architecture Decision Records. Template: Status, Context, Decision, Consequences. Spotify’s guide and endjin’s walkthrough are solid starting points. Triggers: choosing a data source, defining a metric, selecting a materialisation strategy. Start a metrics/CHANGELOG.md with semantic versioning for metric definitions. This feels like overkill until the first time somebody asks why a number changed — then it pays for itself instantly.
Month 1–2: Build the narrative layer. A lightweight Notion wiki with four sections: Metric Definitions (linked to dbt docs), Decision Log, Data Architecture Overview, and Onboarding Guide. Adapt dbt Labs’ PR template to require ‘why’ documentation on every pull request. One approach we’ve used with clients: ‘treasure hunt’ onboarding where new hires must answer five business questions using only documented data models. Gaps become visible immediately — and people are motivated to fix the docs they just struggled with.
Month 3+: Make it agent-ready. Deploy the dbt MCP Server. Build verified query libraries — known-good question-to-SQL pairs for text-to-SQL use cases. Add model contracts on critical output models (contract: enforced: true). The Open Data Contract Standard and Monte Carlo’s 7 implementation lessons are worth reading before you start.
Path B: Fixing context gaps in an existing stack
You have models, dashboards, and accumulated decisions — but most of the context lives in people’s heads and old Slack threads. This is where most of our clients start, so we’ve done this one a lot.
Sprint 1 (Weeks 1–3): Audit and triage. Deploy dbt_project_evaluator and dbt-coverage in CI to measure documentation gaps. Most teams are shocked by their baseline — I’ve seen coverage numbers in the single digits. Identify the 10–15 ‘load-bearing’ models: the ones that power board reports, marketing dashboards, and financial metrics. Document those first. Interview the 2–3 people who built the critical models. Record the ‘why’ before it walks out the door. Seriously — book those meetings this week.
Sprint 2 (Weeks 3–6): Add enforcement. Implement dbt-checkpoint hooks scoped to marts only — don’t block staging work, pick your battles. Datafold’s guide covers integration patterns. Add a mandatory ‘why’ section to PR templates. Assign Documentation DRIs (Directly Responsible Individuals), rotating quarterly so context spreads rather than concentrating in one person. We’ve seen the rotating model work much better than permanent ownership — it forces knowledge transfer.
Sprint 3 (Weeks 6–10): Bridge to business context. For teams under 10 people: Notion plus dbt docs is sufficient. Don’t buy a catalogue yet (I mean it). For teams of 10+: evaluate Secoda for ease of use, OpenMetadata for self-hosted flexibility, or DataHub Cloud for context-first architecture. The decision point we recommend: when Notion and dbt docs can no longer surface context efficiently — typically around 8–10 data people — graduate to a dedicated tool. Consider dbt Power User for VS Code (free, uses AI to generate contextual documentation) or dbt-metalog to turn YAML annotations into queryable metadata models.
Ongoing: Create the AI feedback loop. Deploy AI tools against your documented models and track where they fail. Every failure is a context gap you can fix. Spotify found that when good documentation visibly powers better AI answers, maintaining it becomes self-reinforcing. That’s the key insight: AI creates the economic incentive for solving cognitive debt. We’ve never had that before.
Context is infrastructure
The teams that move fastest aren’t the ones with the best tools. They’re the ones where a new joiner can understand why a metric exists, not just what it calculates.
I think context belongs in the same category as your warehouse, your transformation layer, and your BI tool. It deserves the same rigour, the same budget conversations, and the same engineering attention. The paradox is real: AI makes this both harder and more urgent. But it also — for the first time — creates genuine economic pressure to capture the ‘why’.
So: how are you handling this as people leave and tools multiply?
If you’re staring at undocumented dbt models and wondering where to start, we’ve helped teams build this from scratch in weeks. Happy to compare notes.