TL;DR. Where should the semantic layer live? The dbt vs BI tool vs warehouse vs OSI question matters less than ownership. For most scaling companies, the analytics team should own the semantic layer, working inside the BI tool they use every day. That is how definitions stay current.
Omni closed a $120m Series C on 23 April 2026 at a $1.5bn valuation, led by ICONIQ. ARR is up 4x, and March was its first profitable month. The customer roster includes BambooHR at over 100,000 users, Cribl, Guitar Center, Mercury, and dbt Labs themselves. Colin Zima’s announcement post barely uses the phrase “BI tool”. Omni’s product, he says, is “the context layer”. The dashboards are downstream and clearly Colin’s bet is that the semantic layer is the moat.
The rest of the industry agrees. In the eight weeks around the announcement, the Open Semantic Interchange initiative passed 30 signatories: Snowflake, Salesforce, Databricks, dbt Labs, Cube, Omni, Hex, ThoughtSpot, Sigma, Lightdash, AtScale, Oracle, Qlik, plus the long tail. dbt Labs open-sourced MetricFlow under Apache 2.0. Hex shipped Semantic Authoring with its own YAML spec. As Benn Stancil pointed out, that’s just the latest BI vendor deciding it needs to own the metric layer. Snowflake Semantic Views are GA. Databricks has Metric Views in Unity Catalog. dbt and Omni shipped a first-class integration that maps dbt metrics straight into Omni.
The market has settled the first question: the semantic layer matters. AI analytics needs a governed context layer or the LLM fabricates numbers, confidently and irreproducibly.
Location is the harder question. In dbt? In the BI tool? In the warehouse? Federated across all three through OSI? Every CTO and head of data is being pitched on the answer right now, and for most companies the framing is wrong.
Four answers being pitched
I see broadly four ways of solving this. As with most hard technical decisions, none are obviously wrong. Let’s dive in!
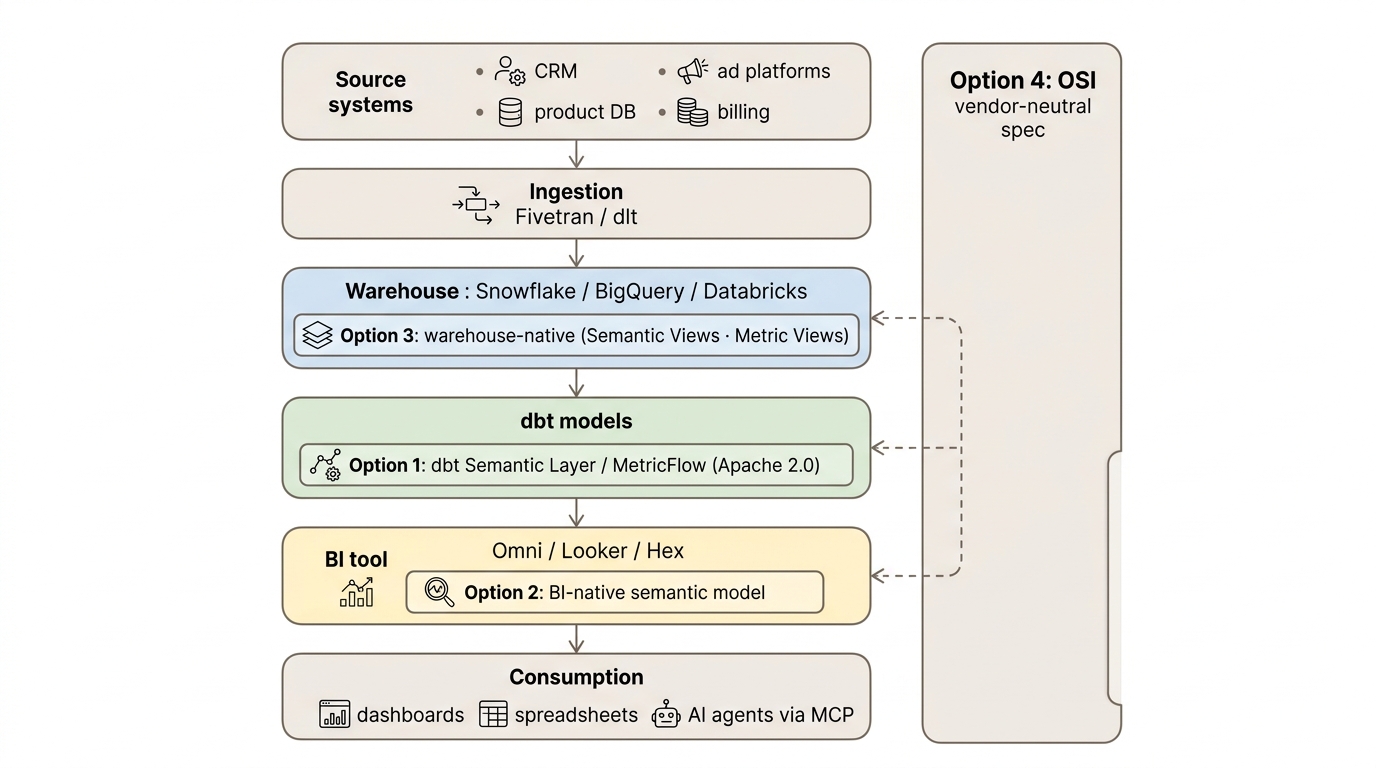
dbt is the engineer’s answer. Metrics in code, in Git, downstream tools all read from one source. MetricFlow’s Apache-licensed now, and the dbt-Omni integration is live. On a whiteboard, you write a metric once and it shows up everywhere: BI tools, AI agents, notebooks. It’s what analytics-engineering Twitter has been asking for since 2021.
The BI tool (Omni, Looker, Hex) is the proximity argument. Put the semantic model where the dashboards live, where the people asking the questions actually sit. The cost is some loss of portability; the gain is a much shorter loop between “this definition needs to change” and “this definition has changed”.
The warehouse (Snowflake Semantic Views, Databricks Metric Views) is the AI-agent play. Push semantics down to the layer everything queries anyway and expose them via MCP. Any agent that speaks MCP gets governed access without a BI tool in the loop. Snowflake and Databricks are betting hard on this one.
OSI is the diplomatic answer. A vendor-neutral spec, so in theory you author once and it translates everywhere: no lock-in, no re-platforming, no redefining ARR for the fifth time in five years. For now it remains a vendor conversation.
All four are defensible. Every vendor deck I have seen this year frames the choice as the big architectural decision a team needs to commit to. The framing is plausible, but it skips the question that actually determines whether any of these layers work in practice
The question the diagrams skip
Architectures don’t go stale, but definitions do – as we learned the hard way over the last six years.
A semantic layer that’s two months behind reality is worse than one that’s messy but current. Confident wrong answers destroy trust faster than no answer does, and the most reliable way to produce confident wrong answers is a definition that hasn’t caught up with last sprint’s product change. By the way, this is exactly why step 1 in our engagements is always to run a proper business logic discovery session – helping our clients align on the exact right definitions before we commit a single line of presentational model code.
It also means that the real challenge in data modelling is always operational. When the product team changes how a feature counts on Tuesday afternoon, who can update the definition by Wednesday morning?
Across our work, we have seen dbt MetricFlow layers that were technically immaculate and three months out of date. We have seen Omni models that started as hacky dashboards and became the source of truth three months later, because someone was actually maintaining them. The most consistent failure pattern, though, is central platform teams owning the semantic layer with great discipline and producing a queue of pending definition changes long enough that the marketing analyst gave up and built her own.
If engineers own the semantic layer, you’re doing it wrong.
Most vendor pitches put engineering or a central platform team in the driver’s seat. Our experience is that this is not quite the right approach.
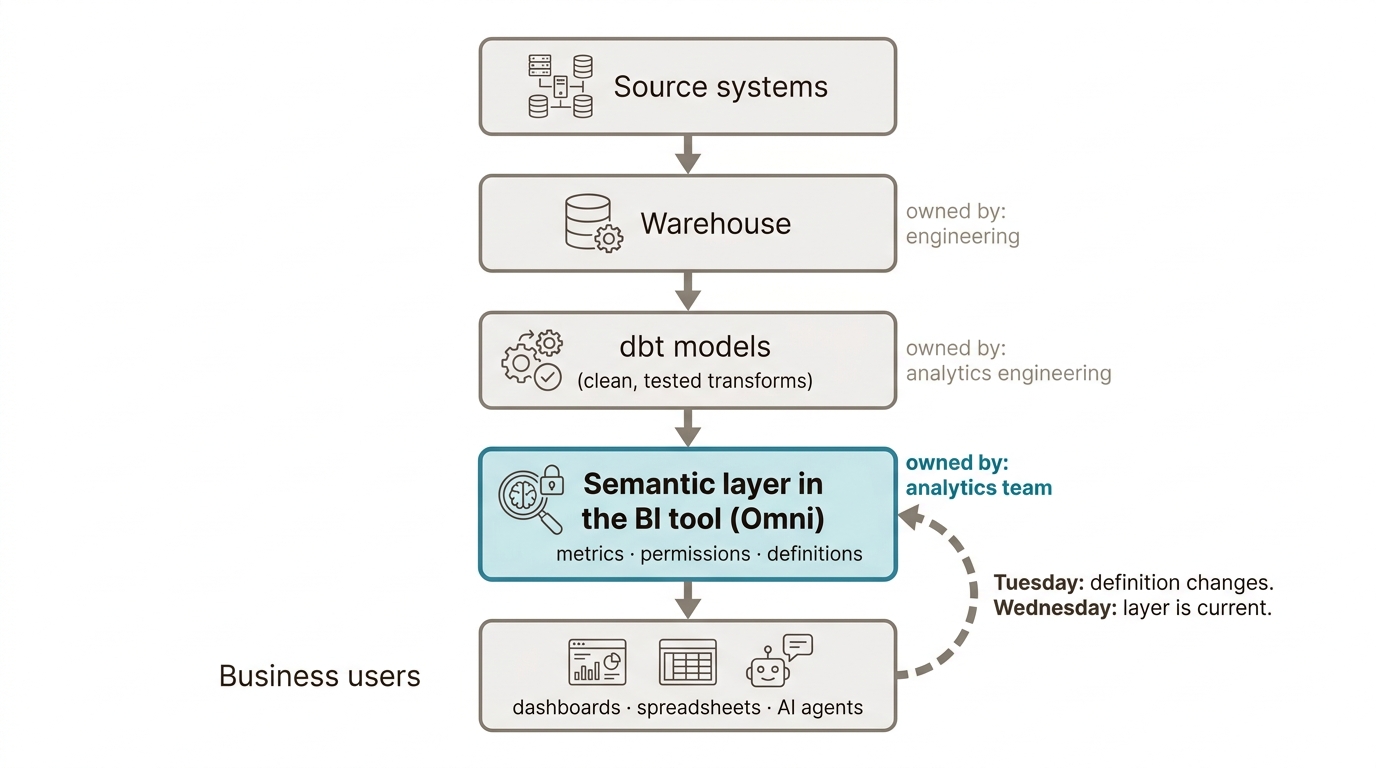
Engineering teams build great semantic layers in the technical sense. Tested, versioned, consistent. They’re still the wrong owners. Engineering optimises for what’s clean and what scales. They don’t get the 4pm Slack asking why the LTV figure doesn’t match the board deck, and they wouldn’t have the context to answer it if they did. The mismatch is one of proximity and cadence.
A central platform team has the same problem with more meetings. Centralisation looks like governance on the org chart but produces queues in practice, and queues are how a semantic layer goes stale. The data-mesh argument applies even at scale-up size: when the bottleneck is meaning rather than infrastructure, the people closest to the meaning need to own the definition.
The analytics team should own the semantic layer because they are the ones on the hook when a definition drifts. They are close to the business and accountable to the people whose decisions depend on the number being right. Give them a tool they can edit without raising a pull request and the layer stays current; make them queue up behind engineering and it doesn’t.
So, where should the semantic layer live?
Ownership decides location more than the other way round. For most scaling companies (50 to 400 people, with one or two analysts already drowning), put the semantic layer in the BI tool the analytics team is in every day. If you’re an Omni shop, that’s Omni. At this size, the dbt Semantic Layer adds maintenance overhead without yet delivering a return. Running two layers in parallel (dbt for purity, Omni for daily use) produces a stale dbt layer and a working Omni layer six months later. Pick one.
dbt MetricFlow becomes worth the maintenance overhead when you genuinely have multiple downstream consumers: three BI tools, an embedded analytics product, or a regulated reporting workflow where defining a metric twice is unacceptable. This is real, but it is not most companies.
Warehouse-native semantics (Snowflake Semantic Views, mainly) earn their place when the warehouse is the centre of gravity and AI agents hit it directly via MCP without a BI tool in the loop. That is a different setup with a different answer.
OSI is a vendor conversation. It is worth tracking, not yet worth implementing. The portability it promises only becomes relevant once a team has a working, current semantic layer they want to port to a second tool, which is a problem most readers will not face for some time.
What the $1.5 billion is actually buying
The semantic layer is the moat for AI analytics; the $1.5bn valuation of Omni makes that thesis explicit. The follow-on point is harder to fit into a fundraising deck: the moat compounds through maintenance discipline as much as through architecture.
A semantic model in Omni that gets updated the day a definition changes is more useful than the perfect dbt-plus-OSI architecture sketched on a whiteboard six months ago and left to drift. The companies whose AI deployments are working in production right now (BambooHR, Cribl and Guitar Center on Omni’s reference list, plus a quieter list of our own) win on maintenance discipline. Someone on their analytics team keeps the meaning current.
Pick the place your team will actually keep current.
Frequently asked
Where should the semantic layer live?
For most scaling companies (50 to 400 people, one or two analysts already drowning), the semantic layer should live in the BI tool the analytics team uses every day. dbt’s Semantic Layer becomes a serious option only when you have multiple downstream consumers: three BI tools, an embedded analytics product, or a regulated reporting workflow where defining a metric twice is unacceptable.
Who should own the semantic layer?
The analytics team. Engineering builds great semantic layers in the technical sense, but engineering is not close enough to the business to keep definitions current. Analytics teams are on the hook when a definition drifts on a Wednesday morning, and that is the operational test that matters.
What is the Open Semantic Interchange (OSI)?
OSI is a vendor-neutral specification for semantic models, backed by Snowflake, Salesforce, dbt Labs, Databricks, Omni, Hex, ThoughtSpot and more than 30 other vendors. The goal is portability of business logic across tools. It is currently a vendor conversation; tracking it is sensible, implementing it is premature.
Should I use dbt’s semantic layer or my BI tool’s semantic layer?
Use the one your team will actually keep current. For most scale-ups that’s the BI tool. Running two semantic layers in parallel (one in dbt for purity, one in the BI tool for actual use) usually produces a stale dbt layer and a working BI layer six months later. Pick one