Most AI agents can’t answer simple revenue questions accurately. Not because the data isn’t there. Because they’re calculating it seventeen different ways—including refunds, excluding VAT, double-counting subscriptions, missing forex conversions. Every query is an adventure in creative accounting.
This is the dirty secret of AI implementation: Companies spending millions on AI infrastructure can’t trust it to answer basic business questions. Why? They’re letting AI query raw database tables instead of building proper semantic layers. The result? Burned compute costs, hallucinated metrics, and executives who’ve lost faith in their data teams. The fix is simpler than you think—and it starts with understanding which tools actually matter at your stage of growth.
Companies that build AI-native data stacks report 90% faster model deployment and 53% improvements in key business metrics. The difference? They understand that AI readiness isn’t about having the latest vector database—it’s about rock-solid data modelling and semantic clarity.

Contents
- Stage 1 – Pre-Revenue to Product-Market Fit (£0-1M ARR)
- Stage 2: Growth Phase (£1-10M ARR)
- Stage 3: Scale Phase (£10M+ ARR)
- Stage 4: AI-Native Operations (£50M+ ARR)
- The Anti-Patterns That Kill AI Initiatives
- The Tasman Difference
Executive Summary: What We Recommend
After six years of building data capabilities, we’ve learned what actually works (and we’ve got the scar tissue to prove it…):
- Business outcomes should drive every decision—not technical sophistication
- AI readiness isn’t about tools, it’s about data modelling and semantic clarity
- Most companies over-engineer too early and under-invest in fundamentals
- The path is clear: Simple analytics → Semantic foundation → AI activation
This guide will save you from the three mistakes that kill AI initiatives: implementing too early, skipping semantic layers, and letting AI touch raw data. Follow this roadmap, and you’ll build a stack that actually delivers value—not just impressive architecture diagrams.
Stage 1: Pre-Revenue to Product-Market Fit ($0-1M ARR)
You’re making bet-the-company decisions daily. Which feature to build next. Which customer segment to pursue. Whether that enterprise deal is worth the customisation. Every choice could be the difference between finding product-market fit or running out of runway. The last thing you need is complex infrastructure slowing you down. What you need is rapid learning—talking to customers, shipping features, testing hypotheses. Your “data platform” at this stage is your ability to move fast and learn faster. Save the sophisticated stack for when you have something worth measuring.
Just Sayin’ It Out Loud: You Don’t Need a Data Stack Yet
Stop. You don’t need a central data platform yet. Here’s what you actually need:
The Minimal Viable Analytics Stack:
- GA4 for website analytics
- Amplitude or PostHog for product analytics (generous free tiers on both: PostHog offers 1M events/month free)
- A Google Sheet for financial metrics and key business indicators
- That’s it. Seriously.
Why this works:
- 80% of early-stage decisions need qualitative insight, not quantitative precision
- Your data volume doesn’t justify infrastructure investment (you’re generating <10GB/month – if more, you’re probably not being selective enough on what you track)
- Every engineering hour spent on data infrastructure is an hour not spent on product-market fit
The Only Exception: When AI Is Your Product
If you’re building an AI-first product (not just adding a ChatGPT layer to your app), skip to Stage 2. You need data infrastructure from day one because:
- Training data quality determines model performance
- You need reproducible pipelines for model updates
- Semantic consistency is critical for AI features
Examples: AI sales assistants, automated analysts, or domain-specific language models all require immediate data infrastructure investment.
What Success Looks Like at This Stage
- You can answer “What features do users love?” in 5 minutes
- Monthly metrics fit on one page
- You’re talking to customers, not building dashboards
- Monthly data cost: $0-500
Stage 2: Growth Phase ($1M-10M ARR)
You’ve found product-market fit, and suddenly everything’s on fire—in the best and worst ways. Marketing wants to double down on channels that work for them, but you can’t agree which ones actually drive revenue. Product needs to know which features drive retention, but your spreadsheets tell different stories. The board wants cohort analyses that take days to pull together. You’re growing fast enough that bad decisions hurt, but not large enough for a full data team. This is precisely when a lightweight, modern data platform becomes your competitive advantage—turning those painful questions into five-minute answers, letting you focus on growth rather than gathering numbers.
The Inflection Point: When Simple Analytics Break
You’ll know you’ve outgrown Stage 1 when:
- The CEO asks “What’s our real CAC?” and three teams give different answers
- “Can you pull this number?” takes days, not minutes
- Marketing and Product have different definitions of “active user”
- You’re losing deals because competitors have AI features
This is your cue to build a proper foundation.
The Minimalist Modern Stack
Based on 2025 research showing companies need modular architectures, here’s the optimal growth-stage stack:
Data Collection Layer:
- RudderStack for event streaming
- Why: Free up to 1M events/month, better pricing than Segment at scale
- Not Segment: Twilio’s acquisition led to 3-5x price increases
- Keep GA4 for marketing attribution (already trained team)
- Keep Amplitude for product analytics (powerful cohort analysis)
Storage & Transformation:
Snowflake for data warehouse
- Why: Superior concurrency handling for growing teams, true zero-maintenance, excellent SQL performance
- Probably Not BigQuery: While cheaper on paper, BigQuery is lagging behind on some important unstructured data features and doesn’t scale as well as Snowflake. The differences are fairly minimal though so if you are already on BigQuery, don’t worry – just build.
- Key advantages:
- Time travel for debugging
- Zero-copy cloning for dev environments
- Automatic query optimisation
- Cost: ~$50-500/month depending on volumes
dbt Core for transformation
- Why: Free, Git-based version control, massive community, 70% of data teams use it
- Consider dbt Cloud if you can afford it: it strips away the devops complexity of Core
- Not dbt Fusion: While Fusion promises to unify a bunch of new tech, it’s still in development. You need proven, stable tools—not beta features. Fusion makes sense at 100M+ events/day, not at your current scale.
The Game-Changer: Semantic Layer
- Omni from day one
- Why: Built for the AI era, not bolted on
- Semantic layer becomes your AI’s “understanding” of your business
- This is non-negotiable—companies with semantic layers see 70% faster AI deployment
Your First 10 Data Models (The Ones You Actually Need)
- customers – Single source of truth for customer data
- products – Product catalog with categories
- transactions – Every revenue event
- events – Unified clickstream data
- prs_customer_metrics – LTV, CAC, activation status
- prs_product_metrics – Usage, adoption, retention
- prs_company_metrics – North star rollups
- prs_marketing_performance – Channel attribution
- prs_product_analytics – Feature adoption
- prs_financial_summary – Revenue recognition
Pro tip: In an ecommerce set-up, these 10 models will answer 95% of your questions. Resist the urge to build more.
Why This Stack Enables AI
The Model Context Protocol (MCP) revolutionised AI-data interactions. Your semantic layer becomes the critical context for an MCP server, providing:
- Safe AI querying: No hallucinated metrics or incorrect joins
- Consistent logic: AI uses your business definitions, not its own
- Performance: Cached aggregations instead of raw table scans
- Security: Row-level permissions enforced at semantic layer
Without a semantic layer, an AI might naively calculate revenue as SUM(amount) including refunds, VAT, and test transactions. With semantic layer, it always uses your validated revenue_recognized metric.
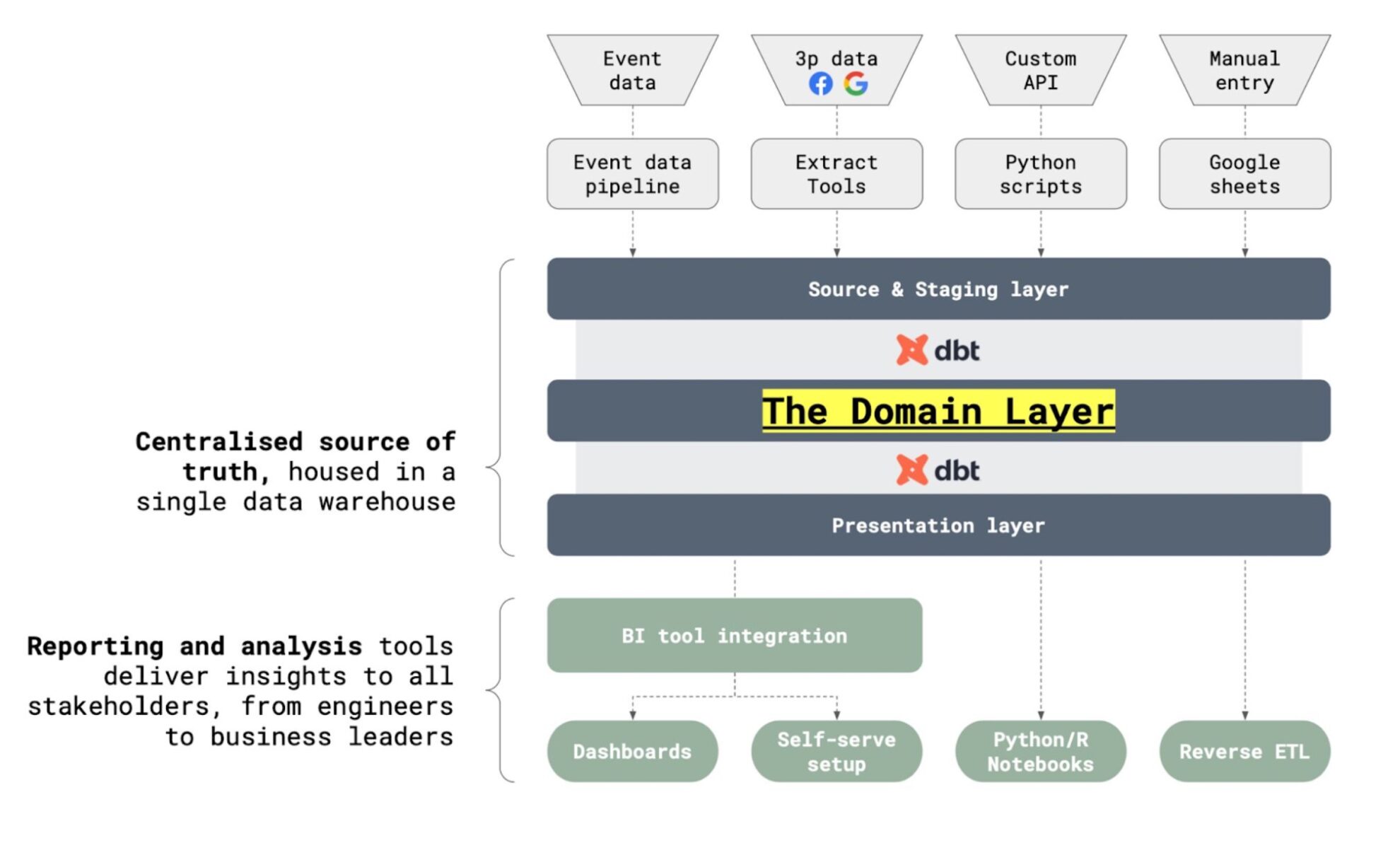
Implementation Roadmap
Sprint 1: Foundation
- Set up RudderStack → Snowflake pipeline
- Implement core tracking plan – don’t forget about doing this properly! It will save you a lot of energy down the line in reconcilation. Use event inspector or a tool like Avo straight away.
- Document key business metrics (and agree on definitions).
Sprint 2: Modeling
- Build first five dbt models
- Establish naming conventions
- Create data quality tests and observability rules.
Sprint 3: Semantic Layer
- Deploy Omni
- Define 20-30 core charts & measures.
- Train team on self-service
Sprint 4: Validation
- Reconcile numbers with existing tools
- Deprecate spreadsheet chaos
- Plan AI prototype
Monthly cost of stack: $500-2,000 (10x ROI within 90 days)
Stage 3: Scale Phase ($10M+ ARR)
You’ve hit the point where gut-feel decisions no longer cut it. Your marketing spend rivals some companies’ entire budgets. Product releases affect thousands of users. Sales forecasts drive hiring plans and inventory decisions. One wrong call on pricing or positioning could cost millions. Meanwhile, your data team is drowning—every department wants custom dashboards, real-time insights, predictive models. The infrastructure that got you here won’t get you there. You need a platform that scales with your ambition, not one that requires a complete rebuild every time you add a new data source or use case.
The Modular Expansion: Only Add What Hurts
You’ve reached scale when any of these are true:
- Data team exceeds 3 people
- You’re managing 20+ data sources
- Real-time requirements emerge (not “hourly is fine”. Real-time streaming.)
- AI moves from experiment to production
Companies at this stage report 304% ROI from platform investments, but only when they maintain modularity so they can scale easily and stay flexible.
Enhanced Collection & Integration
Upgrade event collection:
Consider migrating to Snowplow for enterprise features
- Why: First-party data, no limits, complete control – pricing structure works better with scale
- Handles 1B+ events/day with sub-second latency
Add SaaS integration:
- Fivetran for 500+ connectors
- Why: Set-and-forget reliability, schema migration handling
- Alternative: Airbyte if you need custom connectors
The Platform Decision
Choose based on workload, not hype:
Snowflake if you’re BI-heavy:
- Best SQL performance and concurrency
- Predictable pricing model
- 1,000+ native integrations
- Cost: $25K-30K/year at this stage
Databricks if you’re ML-heavy:
- Unified lakehouse for structured/unstructured
- Native ML workflows
- 50% lower cost for mixed workloads
- Cost: Similar, but more efficient for AI/ML
Recent analysis shows no clear winner—pick based on your use case.
Critical Additions for AI Success
Data Quality & Observability:
- Monte Carlo or Datadog/Metaplane for automated monitoring
- Catches issues before AI serves bad insights
- Companies report 357% ROI from data observability
Activation Layer:
- Hightouch or Census for reverse ETL
- Push AI insights back to operational tools
- Close the loop on predictive analytics
Expanded Semantic Layer:
- Scale Omni to 100+ metrics
- Add role-based access control
- Implement metric versioning
The Data Modeling Imperative
Adopt the “narrow waist” architecture inspired by Apache Iceberg’s design:

Why companies fail here:
- They skip proper modelling (“we’ll fix it later”)—technical debt compounds massively, and the data team bottleneck trap is real (”we’re too busy treading water to think about building a raft”).
- They let AI query raw tables—inconsistent results destroy trust
- They build features without semantic definitions—every team calculates metrics differently.
Monthly cost: $5,000-15,000 (pays for itself in 60-90 days)
Stage 4: AI-Native Operations ($50M+ ARR)
You’re no longer competing on features or price—you’re competing on intelligence. Your competitors use AI to predict churn before customers even think about leaving. Their marketing campaigns self-optimise across channels you haven’t even considered. Their sales teams know exactly which leads to pursue and when. Every manual process in your organisation represents lost revenue and market share. The question isn’t whether to become AI-native—it’s whether you’ll lead the transformation or watch competitors pull ahead. A robust data platform isn’t just infrastructure anymore; it’s the nervous system that lets your entire organisation think and react faster than the competition.
The Full Stack: When Every Decision is AI-Augmented
At this scale, you’re not just using AI—you’re operating AI-first:
- Customer service runs through AI agents
- Marketing campaigns are AI-optimised
- Product features self-tune based on usage
- Financial forecasts update in real-time
The Complete Architecture
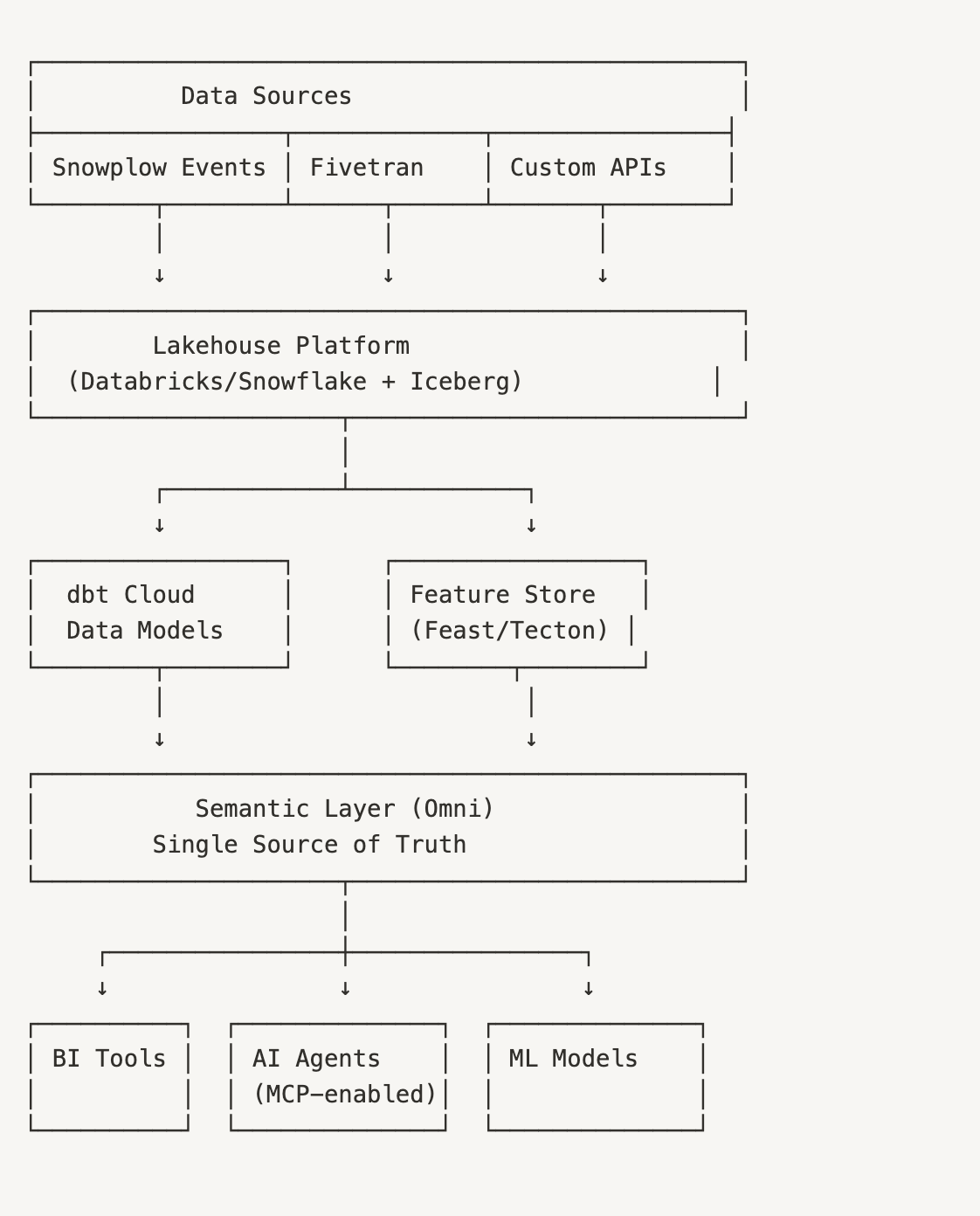
New AI-Specific Components
Vector Databases for unstructured data:
Model Context Protocol Infrastructure:
- MCP server for each business domain
- Standardised tool definitions
- Unity saved $1.3M annually using MCP
MLOps Platform:
The real trade-offs: Business value at every stage
The journey from spreadsheets to AI-native operations isn’t about collecting the latest tools—it’s about making the right trade-offs at the right time. At pre-revenue, you trade infrastructure for customer insights. During growth, you trade perfect architecture for rapid deployment. At scale, you trade simplicity for capability. And when AI-native, you trade some control for transformative intelligence. Each stage demands different sacrifices, but the north star remains constant: delivering measurable business value.
That’s why we obsess over semantic layers before storage optimisation, why we recommend 10 well-modelled tables over 1,000 raw ones, and why we insist on starting small. Your data platform should pay for itself within 90 days at any stage—through better marketing attribution, faster product decisions, or AI-powered insights. If it doesn’t, you’ve built infrastructure, not capability. The best data stack isn’t the one with the most impressive architecture diagram. It’s the one that helps you make better decisions, faster, at a cost that makes sense for your stage. Everything else is just expensive complexity.
The anti-patterns that kill AI initiatives
What actually destroys most AI projects before they deliver value?
First, the “Query Everything” fallacy—giving AI agents direct access to your data warehouse. This creates chaos: inconsistent answers, security nightmares, and astronomical compute costs. Instead, force AI through your semantic layer exclusively. It’s the difference between a toddler with database credentials and a trained analyst with guardrails.
Second, the “Big Bang” migration—convinced you need to rebuild everything for AI, companies embark on 18-month, £4M journeys with 70% failure rates. The reality? Start with a semantic layer over your existing warehouse, add AI for one use case, and then expand based on proven value. Why? Because 90% of AI value comes from 10% of the stack.
The third killer is the “Tool Obsession” trap. Teams accumulate 15 different monitoring platforms, drowning in alerts while missing what matters. They chase the latest AI observability tools while their underlying data crumbles. Just be effective instead: 10 well-modelled tables beat 1,000 raw ones. Clear ownership beats fancy dashboards. Data contracts beat post-mortems. Because here’s what vendors won’t tell you—bad data breaks every downstream system, no matter how sophisticated your AI tools. Fix your foundations first. The flashy stuff can wait.
The Tasman difference: Why this works
Every recommendation in this guide ties directly to measurable business outcomes—we don’t do tech theatre. Choose RudderStack over Segment for 70% cost savings with identical features. Implement Omni from day one to deploy AI 50% faster. Use dbt for modelling to cut data inconsistencies by 90%. Make semantic layers mandatory to achieve zero hallucinated metrics. These aren’t theoretical benefits—they’re proven results from our work with 60+ high-growth organisations. We’ve learnt what actually moves the needle versus what just looks impressive in vendor demos.
The semantic layer isn’t just another tool—it’s the foundation that makes everything else work. With it, AI agents understand your business logic, not just your database schema. New team members become productive in days rather than months because metrics mean the same thing everywhere. Changes to business definitions propagate instantly across every dashboard, report, and AI model. And because we build on open standards—Apache Iceberg for table formats, dbt for transformations, Model Context Protocol for AI interfaces, and SQL for everything else—you’re never locked into a vendor’s roadmap. Your data platform should liberate your business, not hold it hostage.