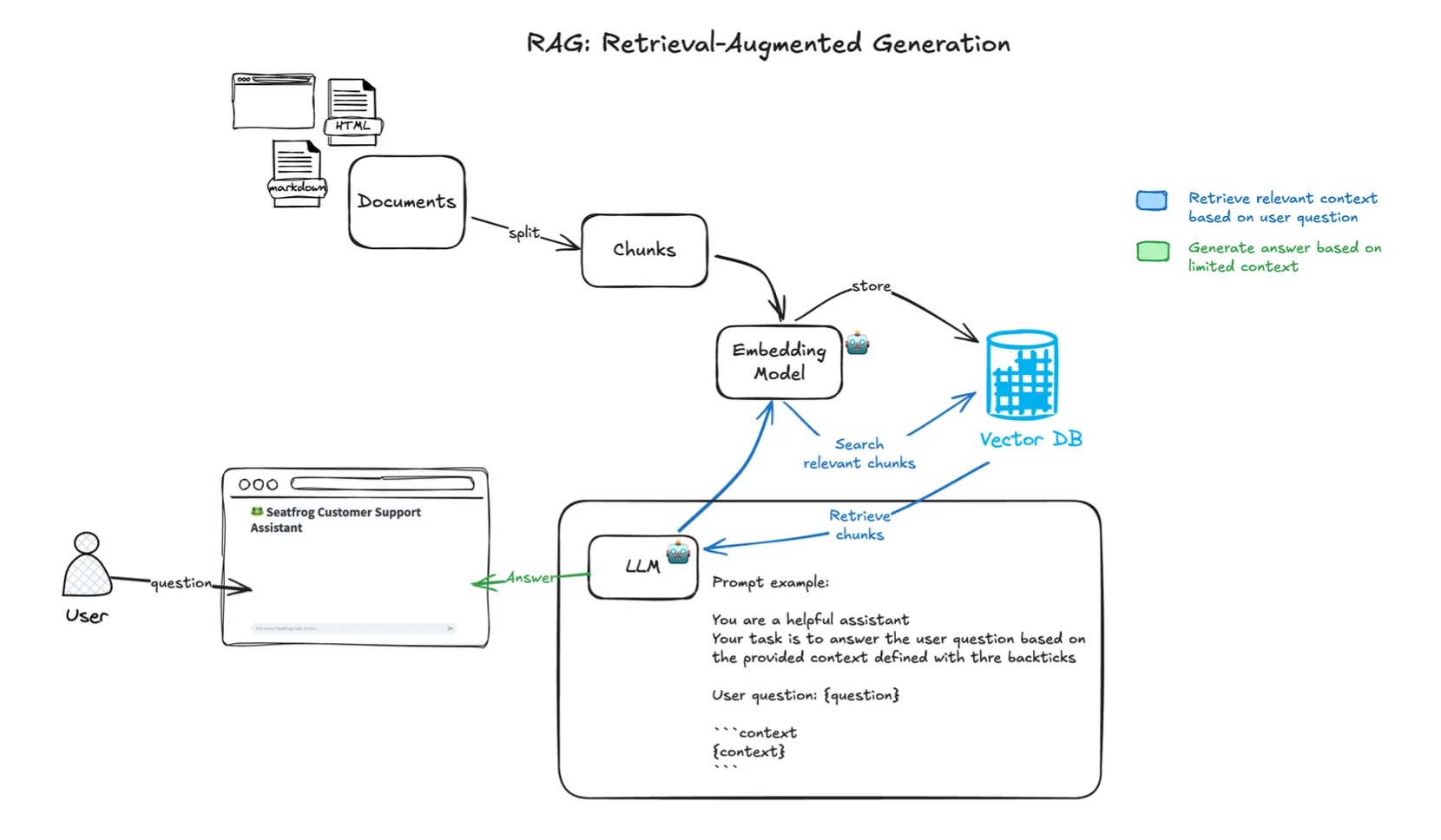
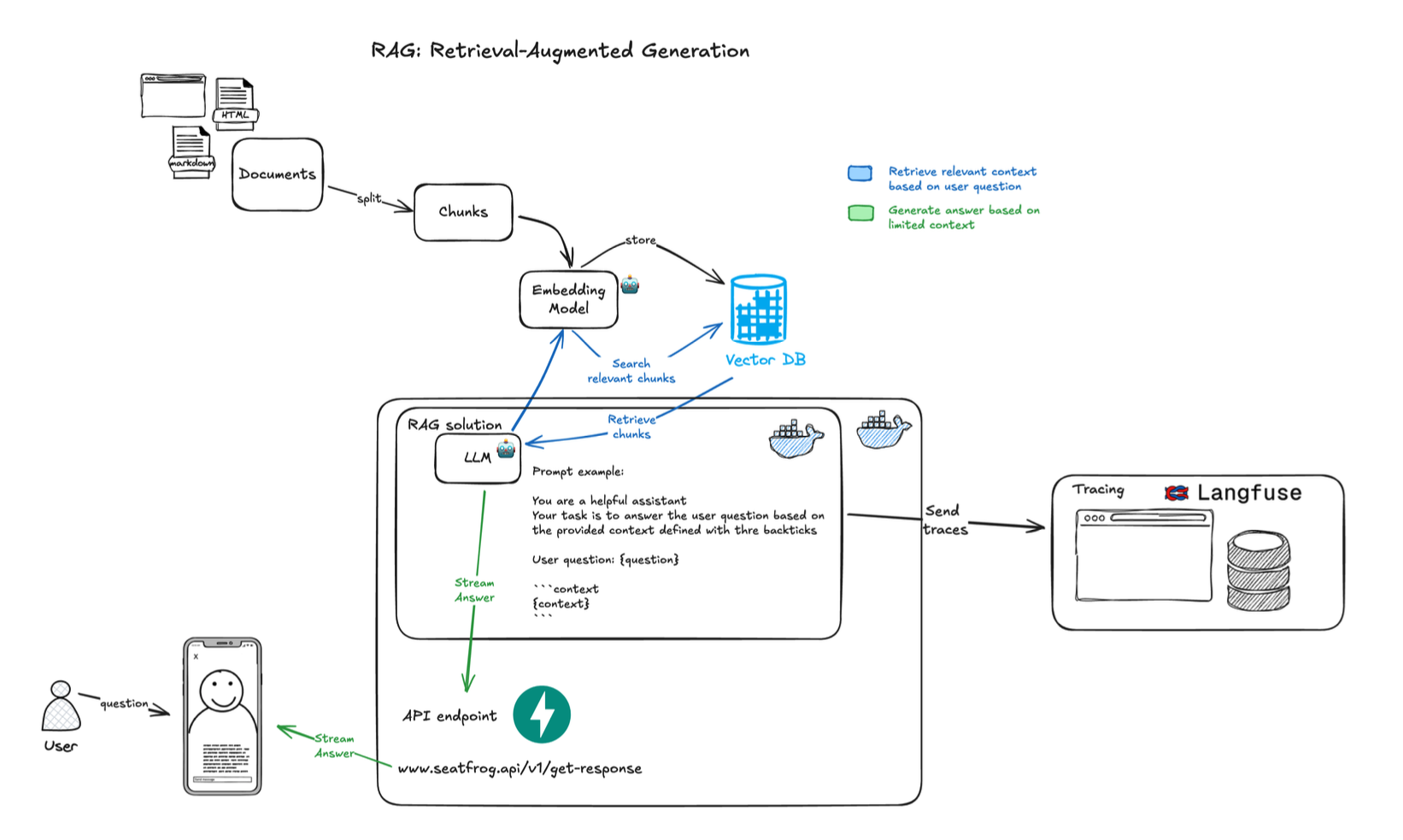
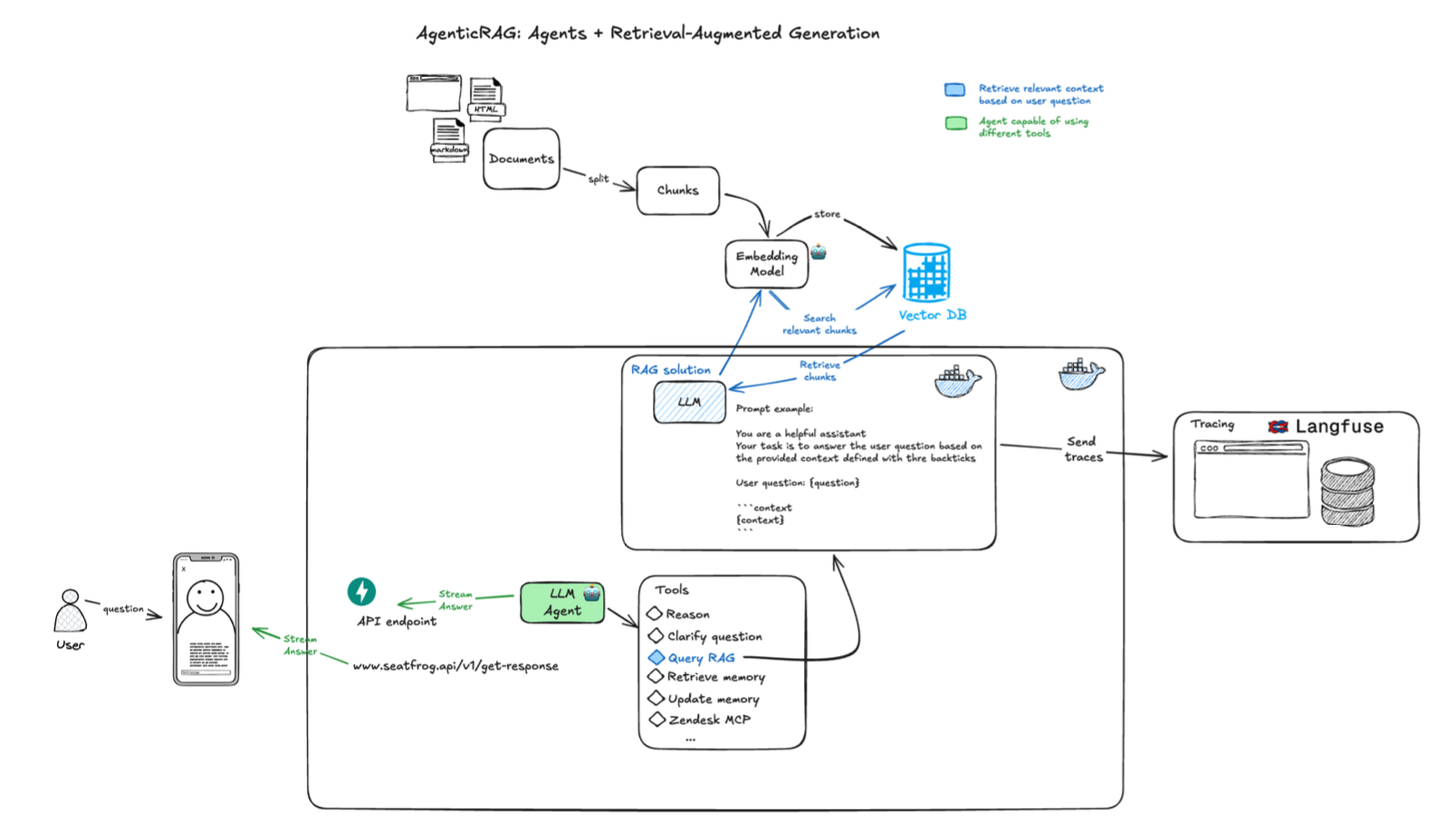
The initial prototype focused on proving the core RAG pattern could handle Seatfrog’s domain complexity. As shown in the system diagram, the data flow begins with comprehensive website crawling that preserves the hierarchical structure of help articles. Rather than naive splitting, the chunking algorithm respects semantic boundaries ensuring that related information about ticket types or refund policies stays together. Key technical decisions included:
- Embedding model: OpenAI text-embedding-3-small (1536 dimensions) for semantic search.
- Context window: No limited, optimally balanced for completeness vs cost.
- Retrieval strategy: Top-4 most relevant chunks with similarity scoring using cosine distance methods.
- Response streaming: Server-sent events for <200ms time-to-first-token.
- Simple UI: Basic chat interface for internal testing and evaluation.
To evaluate the quality and accuracy of generated responses, we worked with the Client Subjet Matter Expert to prepare a curated dataset of questions, the expected answer, and the source URL that should be referenced. This resulted in 12 questions, covering a good variety of use cases, with answers that were concise and feasible to evaluate against the generated responses.
We then implemented a solution for automated testing, leveraging LLM-as-a-Judge approach. We defined unit tests with Pytest, calling a function with parameters: question, expected answer, list of expected sources and generated response. This function was defined with a clear prompt and instructions to provide a structured output consistent with True/False results expected by the assertion tests.
This foundation achieved a 50% success rate on Seatfrog’s test queries, out of the box — this is high, and remarkably close to industry-leading benchmarks whilst using a smaller, more cost-effective model with simple single-turn question and answer. And this is before the fine-tuning and debugging/refactoring existing documentation in the knowledge base.