You’ve read the Data Mesh book. You’ve attended the webinars. Your leadership team is asking when you’ll implement it.
Implementing data mesh sounds straightforward in theory. Yet when most teams attempt a full data mesh implementation, they quickly discover the real challenge isn’t infrastructure but people, processes, and governance. The organisations that succeed combine domain ownership with clear product thinking, embracing data as a product rather than just a collection of raw tables.
In fact, we’ve seen the same pattern repeatedly: teams claiming data mesh implementation victories whilst running everything through a centralised Snowflake instance with well-organised dbt projects. Even Siemens, often cited as the Data Mesh poster child, implements their “mesh” through centralised infrastructure with domain-separated projects not the distributed systems the manifestos describe (Monte Carlo; Nexla).
This shift has major implications for data architecture and data governance. Instead of over-investing in platforms or chasing the promise of fully self-serve data, the winners focus on lightweight practices that scale. They document ownership, define success metrics, and build trust in their data products before adding infrastructure complexity.
At Tasman, we’ve worked with 50+ high-growth companies across Europe, and the pattern is clear: you don’t need a distributed platform to see results. You need the right balance of ownership, governance, and product discipline.
Here’s what we’ll talk about:
- Why domain ownership and responsibility matter more than infrastructure
- When your company is actually ready for a data mesh implementation
- Tools that empower domain ownership in teams
- Why you should build data products first, not platforms
- A realistic roadmap from pilot to scale
- Data Product Brief Template
- When distributed infra is worth the cost
- Common pitfalls to avoid
- Why ownership + governance drive success
- Your Realistic Data Mesh Implementation Roadmap
Why Domain Ownership and Responsibility Matter More Than Infrastructure
Let’s address the elephant in the room first.
When companies tell us they’ve “implemented Data Mesh,” what we actually find is remarkably consistent: a central data team with good documentation, clear boundaries, and domain-specific folders in their dbt project. This isn’t a failure it’s pragmatism winning over architectural purity.
The successful implementations we’ve observed are 90% organisational and 10% technical. The wins come from domain ownership combined with treating data as a product, not from distributed infrastructure (read more on ‘Domain modelling how to’). Teams succeed when they establish clear ownership, implement proper product briefs for their data assets, and document dependencies properly. And they fail when they attempt distributed systems, create federated data governance committees, or collect data without clear user needs in mind (Medium – Hannes Rollin; ThoughtWorks).
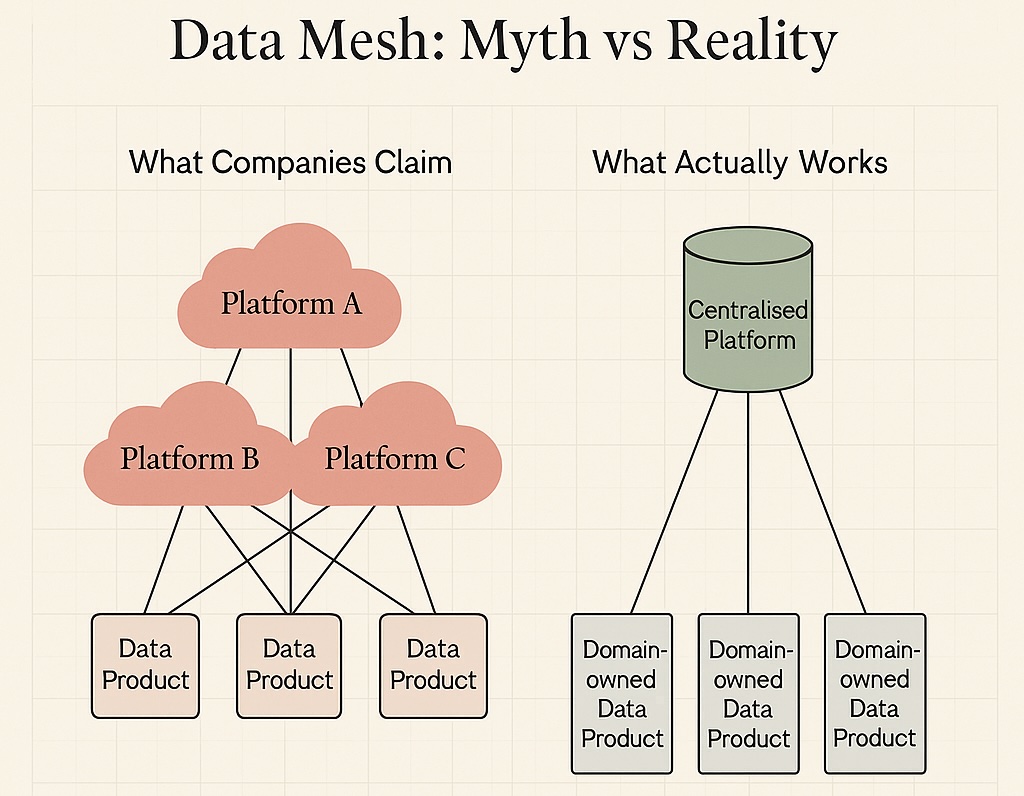
Consider what this looks like in practice: each domain owns their logic, defines their metrics, and maintains their models. But crucially, they approach each data asset as data as a product to be manufactured with intention not just data to be collected and hope insights emerge. Everything runs on the same Snowflake instance, uses the same dbt Cloud project, and shares the same Fivetran or Airbyte connections. This approach delivers the organisational benefits of Data Mesh without the infrastructure complexity.
Choosing the Right Time for a Data Mesh Implementation (Based on Company Maturity)
Here’s an insight that could save you months of architectural debates: your business model maturity determines your data architecture, not the other way around.
But there’s a second dimension that’s equally important: your data product maturity determines whether any data architecture will deliver value.
Pre-Product-Market Fit (Seed to Series A): Why Data Architecture Should Stay Simple
When your business model changes monthly, building elaborate data architecture is like pouring concrete whilst dancing. Yesterday’s “customer” becomes today’s “user” and tomorrow’s “account.”
Data Product Approach: Even at this stage, start with user needs. Who needs what information to make which decisions? This typically results in a massive increase in dashboard usage and faster decision-making (Daappod).
Scaling Phase (Series B-C, 50-200 people): Building Self-Serve Data Practices
Your business model is solidifying. Core entities like customer, product, and transaction are stabilising. Domain ownership boundaries are becoming clear – marketing knows what they need, sales has consistent requirements, and product has established metrics.
Data Product Approach: This is when you start writing proper product briefs for each data initiative. Transform vague requests like “we need marketing dashboards” into concrete specifications: “marketing needs to see CAC by cohort, campaign and geo every day to make sub-48 hour optimisation decisions.”
Maturity Phase (200+ people, stable model): Embedding Data Governance into Teams
Your business model has been stable for at least a year. Domain boundaries are crystal clear. Teams have dedicated data people.
Data Product Approach: Now you can implement full data product management at domain level. Each domain doesn’t just own their data they manufacture insights as products with defined users, quality standards, and success metrics. Attempting distributed Data Mesh infra before this point risks serious cost and complexity (Medium – The Brutal Cost of Data Mesh).
Tools That Empower Domain Teams
The modern data stack (read more on ‘Lean data stack: cost-efficient modern data solutions’) has evolved to support data mesh implementation through domain autonomy and data product management without distributed infrastructure (AWS; Microsoft Learn).
Infrastructure Layer
- Snowflake/BigQuery: Use schemas and databases for logical domain separation
- dbt: Separate projects or folders by domain, with clear
ref()dependencies - Fivetran/Airbyte: Centralised ingestion with domain-specific connectors
Product Management Layer
- Documentation: Product briefs in your repo (start simple!)
- Monitoring: Track usage and quality per data product
- Feedback: Regular surveys and usage analytics
Governance Layer
- Contracts: Simple YAML files defining interfaces between domains
- Quality: Automated testing tied to product quality requirements
- Discovery: Modern catalogues that understand product boundaries
Build the Data as a Product First Not a Distributed Platform
The genius of Data Mesh isn’t just in its domain orientation it’s in treating data as a product. But you don’t need distributed infrastructure to manufacture high-quality data products. Here’s how to implement each core principle through a product lens.
1. Domain-Oriented Data Manufacturing
What the theory says: Each domain runs their own data platform, choosing their own tools and maintaining their own infrastructure.
What actually works: Each domain owns their data products within a shared platform, but with proper product management discipline.
Instead of asking “What data can we collect?” domains ask “Who needs what information to make which decisions?” This simple reframing transforms how you approach data collection and data architecture. It also ensures data as a product thinking naturally aligns with governance requirements, reducing data governance challenges down the road. Each domain maintains:
- Product briefs for their key data assets
- User personas for their data consumers
- Success metrics for their data products
- Quality standards appropriate to their use cases
2 What “Data as a Product” Really Means
What the theory says: APIs, SLAs, versioning, product managers for data, treating internal consumers as customers.
What actually works: Structured product briefs, clear ownership, and documented contracts – without building actual APIs.
Here’s what a practical data product brief looks like:
PRODUCT BRIEF: Marketing Attribution Dashboard
INTENT: Enable marketing team to optimise spend allocation across channels
based on true attribution impact
PRIMARY USERS:
- Marketing operations (daily optimisation decisions)
- CMO (weekly budget allocation)
- Finance (monthly ROI reporting)
KEY DECISIONS SUPPORTED:
- Which campaigns to scale or pause
- Where to allocate next month's budget
- Whether to test new channels
QUALITY REQUIREMENTS:
- Data freshness: < 2 hours for digital channels
- Accuracy: 95% match with source systems
- Completeness: No gaps in attribution chain
SUCCESS METRICS:
- Time from campaign launch to first optimisation: < 48 hours
- Marketing efficiency improvement: 15% within first quarter
- User adoption: 80% of marketing team accessing weekly
This provides all the benefits of treating data as a product – clear ownership, documented interface, quality guarantees – without the overhead of building actual APIs or managing complex versioning (Monte Carlo; Medium – Wannes Rosiers).
3. Product Discipline at Scale
What the theory says: Build a platform that abstracts all complexity, allowing domains to spin up their own data capabilities.
What actually works: A modern stack with proper product management processes, not additional abstraction layers.
A retail client of ours cut their pipeline costs by 70% whilst simultaneously increasing actionable insights by focusing exclusively on data products directly tied to their growth metrics. They achieved this through:
- Repository templates with standard product brief formats
- Weekly reviews of data product usage and value
- Clear prioritisation frameworks (not all data is equally valuable)
- Regular feedback loops with users
The platform is the modern data stack itself – Snowflake, dbt, Fivetran – but the value comes from the product discipline applied on top.
4. Federated Product Management
What the theory says: Distributed decision-making with autonomous domains setting their own standards.
What actually works: Central team establishes product management framework, domains own their specific implementations.
Each domain maintains ownership of their data products but within a shared framework:
- Central team defines core entities everyone depends on
- Domains extend these for their specific needs
- Product briefs ensure alignment without committees
- Success is measured by usage and value, not architectural purity (Monte Carlo)
A Practical Path from Pilot to Scale
Based on our experience across dozens of implementations, here’s how to combine data mesh thinking with proper data product management:
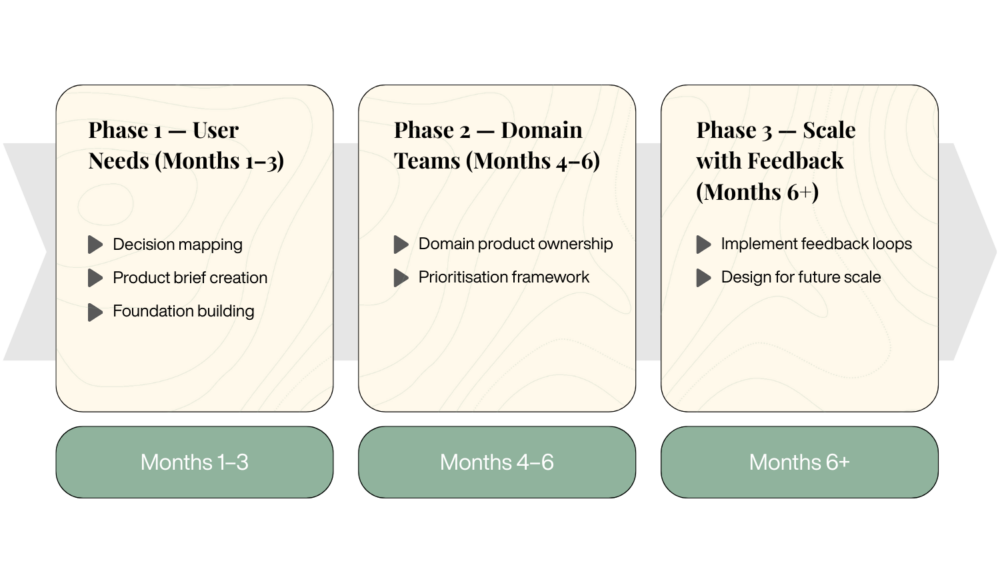
Phase 1 – User Needs and Data Product Foundations (Months 1–3)
Week 1–2: Decision Mapping
- Interview key stakeholders about their critical decisions
- Document what information would make those decisions better
- Identify gaps between current data and decision needs
Week 3–4: Product Brief Creation
- Write a one-page brief for your three most critical data products:
- Who uses it?
- What decisions does it support?
- What quality standards are required?
- How will we measure success?
Month 2–3: Foundation Building
- Only now do you start building, but with clear product intent, laying the foundation of your data architecture for future growth:
- Core entities that multiple domains need
- Basic quality monitoring
- Simple documentation standards
One transportation client leveraged their initial product-focused design to build machine learning models two years later without requiring any data rework—all because they designed with future scale in mind from day one.
Phase 2 – Enabling Domain Teams Through Ownership (Months 4–6)
Give each domain the ability to manufacture their own insights:
Domain Product Ownership
- Each domain writes product briefs for their data assets
- Domains own their entire data product lifecycle
- Central team provides framework and core entities
Prioritisation Framework
- Not all data products are equal. Successful teams focus on highest-impact use cases:
- Revenue-driving metrics first
- Operational efficiency second
- Exploratory analysis third
Being great at metrics prioritisation also makes your data team a strategic asset for organisational growth. As analysts, you’re often the only people who truly understand all the moving parts.
Phase 3 – Scaling with Feedback Loops in Data Governance (Months 6+)
Implement Feedback Loops
- Track usage patterns of reports and dashboards
- Schedule monthly reviews with stakeholders
- Sunset unused data products (yes, really)
Without these feedback mechanisms, even well-designed data products gradually drift from business reality, leading to decreased trust and usage over time.
Design for Future Scale
Whether adopting purpose-built tools or building internal solutions, having systems that support structured design and enforce standards makes all the difference. This isn’t about over-engineering it’s about thoughtful design that pays dividends later.
For teams looking for a lower-barrier path, minimum viable data mesh concepts have been well-documented (Daappod; Paul Andrew).
Data Product Brief Template (Steal This)
Ready to start treating your data as a product? Here’s our lightweight template:
DATA PRODUCT BRIEF: [Name]
INTENT: [One sentence on why this exists]
PRIMARY USERS:
- [Role]: [How often they use it]
- [Role]: [Key decisions they make]
KEY METRICS/DIMENSIONS:
- [What you're measuring]
- [How it's segmented]
SUCCESS CRITERIA:
- [Specific, measurable outcome]
- [Usage target]
- [Quality standard]
OWNERSHIP:
- Product Owner: [Domain/Person]
- Technical Owner: [Who maintains it]
- Review Cycle: [How often you validate it's still needed]When (If Ever) to Invest in Distributed Data Infrastructure
Based on our experience, true distributed Data Mesh infrastructure only makes sense when all of these conditions are met:
- Your business model has been stable for 2+ years
- You have 10+ true product domains with clear boundaries
- Each domain has mature data product management
- Each domain has dedicated data people who understand product thinking
- You’ve outgrown centralised infrastructure despite optimisation
- Domain boundaries have been stable for 18+ months
Until then, manufacture insights through proper data product management on centralised infrastructure. Even companies like Peak, with their 10x growth in subscriber numbers, succeeded with this approach (TechCrunch – Nextdata; IBM).
Common Pitfalls: Data Governance Confusion & Ownership Gaps
❌ The Collection Obsession
We see teams collecting everything “just in case” without clear user needs. This results in a cycle of distrust and endless data cleanup that prevents focus on high-value analysis.
Instead: Start every data initiative with the question: “Who needs this to make what decision?” If you can’t answer clearly, don’t build it.
❌ The Governance Committee Theatre (a classic data governance challenge)
Weekly 2-hour meetings about field naming conventions whilst no one actually uses the data.
Instead: Let usage drive data governance. Focus on the data products people actually depend on. Perfect naming for unused tables is worthless.
❌ The Platform Before Products Trap
Building elaborate self-serve data platforms before you know what products domains actually need to build.
Instead: Start with manual processes, understand the patterns, then automate. A spreadsheet template for product briefs beats a complex platform every time.
❌ The “Build It and They Will Come” Fallacy
Creating dashboards and reports without defined users or success metrics, hoping insights will emerge naturally.
Instead: Make a rule that no data product ships without a product brief. This simple rule transforms data quality and usage across your organisation (TechTarget).
Why Ownership + Data Governance Win (The Business Case)
When we work with clients, the results of combining data product management with domain thinking consistently outperform pure architectural approaches.
Traditional Data Mesh Implementation (Infrastructure Focus)
- Time to first value: 6–12 months
- Significant platform engineering required
- High ongoing maintenance burden
- Value often unclear to business stakeholders (CastorDoc – ROI of Data Mesh; Nexocode)
Data Products + Domain Thinking (Our Approach)
- Time to first value: 4–8 weeks
- Uses existing modern stack
- Clear ROI on each data product
- Business stakeholders understand and engage
The shift in thinking from collection to manufacturing may be subtle, but the impact on your data quality and business outcomes is profound (Techtarget).
From Ownership to Governance: Your Realistic Data Mesh Implementation Roadmap
Ready to manufacture insights at domain scale without the infrastructure mess?
- Start with one data product: Pick your most critical dashboard or report. Write a proper product brief. Measure its success.
- Identify your domains: But don’t build separate infrastructure. Give them ownership through process, not platforms.
- Prioritise ruthlessly: The best data teams say “no” more than “yes.” Each additional metric comes with maintenance costs.
- Create feedback loops: Data products need ongoing refinement just like customer-facing products.
- Document everything: Good documentation enables autonomy better than any platform abstraction.
Remember, you don’t need distributed data infrastructure. You need distributed data thinking combined with proper product management. Focus on manufacturing insights that drive decisions, not collecting data that might someday be useful (read more on ‘Are you manufacturing insights or just collecting data?’).
Start small. Select one decision area and create a proper data product brief. The combination of domain ownership and product discipline will transform how value is created from your organisation’s data assets. That’s what actually works.
FAQs on Data Mesh Implementation
Is Data Mesh a decentralized data collection model?
No. Data mesh implementation decentralizes ownership of data products but usually runs on centralized infra. It’s about data governance, not scattering data.
What are the main challenges?
Key data mesh implementation pitfalls include unclear ownership, governance silos, lack of self-service, and cultural resistance.
When should a company adopt Data Mesh?
When domain boundaries are clear, domain ownership is strong, and federated data governance is possible.
How can we avoid governance theater?
By using briefs, lightweight governance, and usage-driven feedback loops, not committees.