Tasman loves Claude Code and most of us have integrated it into our workflow. I used it for documentation, quick vibe coding sessions, and to mess around with over the weekend. But never for production usecases (where our attitude is still that line-by-line copiloting is more efficient in the long run). Let’s stress-test it by building a Python synthetic data engine using Faker.
When you’re delivering data platforms for high-growth companies, you can’t afford to experiment blindly with AI coding tools. You need to understand their strengths, limitations, and optimal use patterns. The best way to do that is to try and build a production-ready system with it.
And so I was looking for a nicely contained project to do this with. And the main requirement popped up naturally: we LOVE talking about our internal agentic & deep insight capabilities, and there’s no better way to demonstrate this then to, you know, show it. But for obvious reasons we can’t do that with real client data.
In the past we used our own delivery datasets, but they are limited in scope and are not that easily made relevant for most client usecases. And there’s not that many sample datasets out there which meet our needs.
So – let’s build our own using Faker. And actually – a synthetic data generator project is a perfect learning laboratory: complex enough to be meaningful, isolated enough to be safe, and valuable enough to justify the investment.
The result was 24 hours of intensive exploration that fundamentally changed how I think about AI-assisted development.
The Reality of AI-Assisted Coding
AI-assisted coding exists on a spectrum. On one end, there’s line-by-line copiloting—safe, controlled, incremental. You maintain complete oversight, reviewing every suggestion before it enters your codebase.
On the other end, there’s full agentic coding—handing over entire features to an AI system. Most production work lives firmly at the controlled end of this spectrum, and for good reason.
But synthetic data generation presented an ideal case for pushing further:
- the output is clearly verifiable (does the data look realistic?),
- extensively testable (do the statistical distributions match expectations?),
- and limited in scope (it doesn’t touch production systems).
This made it perfect for exploring what Claude Code could really do when given more autonomy.
Maintaining Control in the Age of AI Development
The biggest risk with AI coding tools isn’t that they’ll produce broken code. It’s that they’ll produce working code you don’t understand. One-shot solutions might seem impressive, but they’re antithetical to good software development. You lose the ability to debug, extend, and maintain.
That’s why I wanted this project to follow very strict principles:
- iterative development with clear checkpoints,
- explicit requirements before each coding session,
- immediate performance testing after each iteration,
- and comprehensive documentation throughout.
I wanted to retain complete control over the architecture while leveraging Claude Code’s ability to handle the implementation complexity. The goal wasn’t to replace human judgment but to amplify it—using AI to execute detailed specifications faster than humanly possible while maintaining the architect’s vision and business understanding.
And software engineering practices are key here: separate concerns as much as possible, be very clear about outputs, and think through tests!
That’ll make your flow like this:
- Architect. Produce a data product briefing document with scope (what should it do, what could it do, what should it certainly not do), requirements (intended users, scalability, etc) and acceptance criteria (description of end state). ChatGPT 5 is really good at this at this point, in my experience (and others).
- Use the prompt document from Step 1 as a basis to have Claude Code (or Codex) build an implementation plan. Do not start coding here – instead, ask it to review its plan and break it up into pieces as small as possible.
- Then – ask it to define tests for each of those steps. And then write the entire plan into a text file for version control and manual review.
- At that point you can ask Claude Code to go through the plan, item per item. After every step (e.g. “build out the function to generate the ad spend dataset”), confirm that it actually works and that the tests are validated.
- Repeat!
So – that means that we should start with architecting the scope here.
Part I: Genesis – Setting the Foundation
I first used ChatGPT to write the overall project brief. ChatGPT 5 is very good in thinking through edge cases and being really prescriptive – and it helps to combine LLMs (even if not fully testable my experience is that it helps reduce hallucination / wrong focus risk!)
I want to build a sample dataset for a marketing analytics project. Focus on ecommerce or equivalent.
I’d need to be able to load it into a Snowflake or equivalent warehouse, and have it cover
- marketing spend (e.g. on Meta, Snapchat, Google Ads) against campaigns, adgroups, creatives, dates and the likes
- website visits with UTM tags so I can attribute to marketing spend, ideally already attributed properly. Bunch of organic traffic as well of course. Sessions also tagged, page views, link click stream, etc.
- ecommerce data so i know which visitors purchased what.
- ecommerce context data e.g. SKU, product types, etc.
All with timestamp or date granularity over sufficient history and based on real data.
I’ll then use it to build and test an agent on.
What is the best way to get this at sufficient quantity, say over a three month period?
ChatGPT’s response shaped the architecture:
“Three routes exist… Go synthetic (Option 2). You need high volume, clean schema, and guaranteed links between spend → visits → orders.”
The benefit of this approach is that I already have a project defined in ChatGPT with detailed context about what we do at Tasman (our business model, the type of work we do, the challenges we face, and much more). And that type of context is key in my view. See the full conversation here – I did iterate a bit to ensure the final architectural prompt was suitable.
The Master Prompt to Claude Code
ChatGPT wrote me a detailed prompt that I could use as a starting position for Claude Code. It already architected the basic foundations for the app. This is best practice as I ended up significantly editing this!
You are Claude Code. Generate a self-contained Python project that produces a
realistic, relational, synthetic ecommerce + marketing analytics dataset suitable
for loading into Snowflake. Include a prototype flag to switch between a small
toy dataset and a full 3-month dataset.
Deliverables:
- generate_data.py – main script with CLI
- config.py – tunable parameters and distributions
- schemas.py – column specs and Snowflake DDL
[...]
Target table list and exact schemas (use these names and orders)
Dimensions:
- dim_customers(customer_id STRING, first_visit_date DATE, region STRING,
loyalty_segment STRING, primary_device STRING)
- dim_products(sku STRING, category STRING, subcategory STRING, brand STRING,
price NUMBER(10,2), margin_pct NUMBER(5,2))
[...]
What worked well here:
- Explicit file structure requirements
- Clear pointers to tools (I asked it to build everything on top of Python’s excellent Faker library)
- Exact schema definitions with data types
- Clear volume targets for prototype vs full modes
- Specific business logic requirements.
Testing – it works! It just takes way too long to build the full data set. And so the first iteration prompt is this:
"The data generation is taking over 24 hours for just the prototype dataset.
This is way too slow. Can you optimize this to run much faster? Focus on:
- Removing algorithmic bottlenecks
- Improving complexity from O(n²) operations
- Using vectorisation where possible
- The main issue seems to be in session tracking and organic uplift calculations"
And that worked – Claude identified a module that was introducing O(n²) complexity in looping through all customers and all sessions to check whether there was a link. A stupidly naive error which points to how important not just unit testing is but also how important performance is. It then built an elegant vector implementation which worked much better.
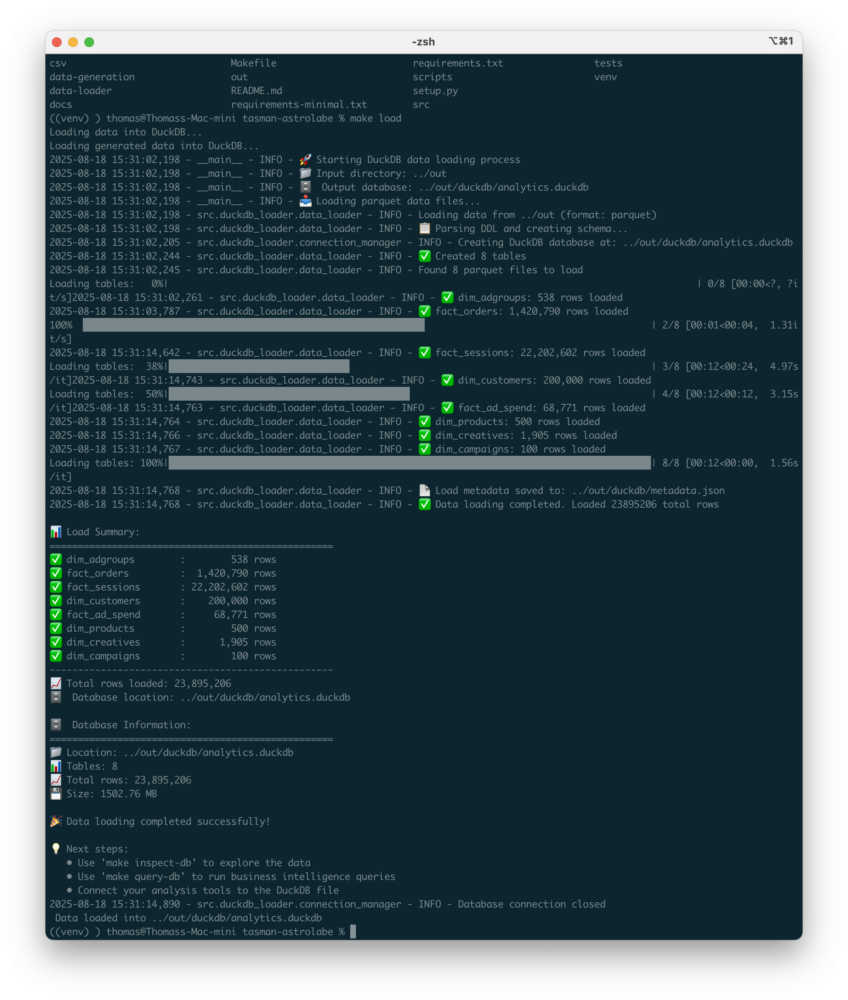
And so we got this to work and have the data loaded into a local duckdb instance for testing & analysis. All in about half a day of work and with an internally consistent, highly configurable setup that is scalable (and testable) from the start.
The next step was to make this more useful and build agentic analytics on top — more on that in our next post where we can also share an open source version 🙂 Sign up for our newsletter to make sure you get it!
Frequently Asked Questions
How does Claude Code compare to GitHub Copilot for complex data projects?
Claude Code excels at architectural tasks and full-feature implementation when given proper constraints. While Copilot works brilliantly for line-by-line suggestions within your IDE, Claude Code handles entire modules with context awareness. In our 24-hour sprint, Claude Code generated complete Python classes with proper error handling and performance optimisation—moving from O(n²) to vectorised operations after a single prompt. For production work, we still prefer Copilot’s incremental approach. For bounded experiments like synthetic data generation, Claude Code’s autonomous capabilities shine.
What makes synthetic data generation an ideal use case for AI-assisted development?
Three characteristics make it perfect: verifiable output (you can immediately see if the data looks realistic), extensive testability (statistical distributions either match or they don’t), and limited scope (it won’t break production systems). Unlike building customer-facing features where edge cases hide everywhere, synthetic data has clear success criteria. Our Faker-based implementation could generate 100,000 customer records with realistic purchasing patterns in under an hour—something immediately validatable through basic SQL queries.
Should we trust AI-generated code for production data platforms?
Not without the right controls. Our approach maintains human oversight at every checkpoint: architect the solution manually, break implementation into testable chunks, review after each iteration, and maintain comprehensive documentation. The risk isn’t broken code—it’s working code you don’t understand. That’s why we used ChatGPT for architecture, Claude Code for implementation, and manual review between each step. Think of it as amplified development rather than autonomous development.
What’s the actual time saving when using Claude Code for data engineering tasks?
For this synthetic data project, what would typically take a week of development compressed into 24 hours—roughly 5x acceleration. But raw speed isn’t the metric that matters. The real value comes from rapid iteration on data schemas and business logic. We modified our entire customer segmentation model three times in an afternoon, something that would typically span multiple sprints. For exploratory data work and proof-of-concepts, expect 3-5x speed improvement. For production systems requiring extensive testing and documentation, 1.5-2x is more realistic.