
Unlike most OLAP DBMS platforms, it’s not meant to be used as a data warehouse — although it can be! So what is DuckDB good for? We’ll go through 8 DuckDB use cases below.
DuckDB use case 1️⃣: Crunch big CSVs
We’ve all been there: you’ve been sent a giant CSV file with hundreds of columns and too many rows to fit in Excel.
How would you usually interrogate this file? A Jupyter notebook with Pandas? Bulk loading the CSV into your existing data warehouse?
DuckDB’s SQL dialect lets you query CSV files directly, without needing any Python or needing to bulk load the file. It also has the best CSV parser in the world (by the Pollock Benchmark) and can read huge CSVs fast.
select *
from 'path/to/file.csv'
Not sure where to run the DuckDB SQL? You can just install the command line version and then use the built-in notebook-style UI with the duckdb -ui command!
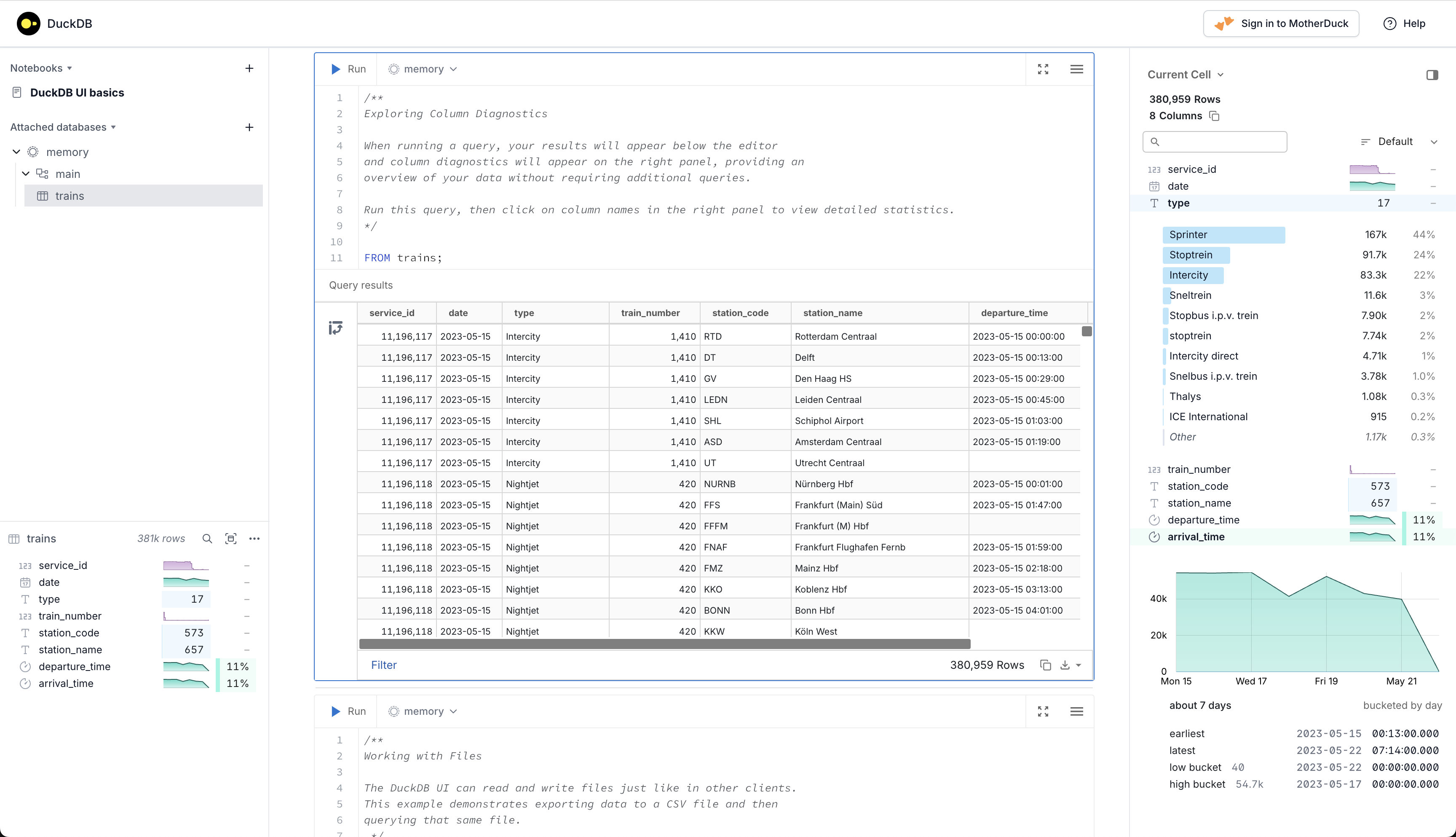
Source: https://duckdb.org/2025/03/12/duckdb-ui.html
DuckDB use case 2️⃣:Crunch JSON files
CSV files aren’t the only type of file that you can query directly with DuckDB.
In additional to tabular file formats (like CSV, Parquet, and other RDMBS), DuckDB also understands JSON and can easily read JSON files:
select property_1, property_2, unnest(property_3)
from 'path/to/file.json'
DuckDB will parse the top-level attributes into columns and top-level array into rows, but you can easily parse nested JSON with the unnest function.
Pro tip: use the recursive:=true argument in the unnest function to recursively unpack nested JSON!
Check out more tips and tricks in DuckDB’s own blog post on shredding JSON in here:
DuckDB use case 3️⃣: Local analysis
Since DuckDB makes it extremely easy to interrogate local files, it’s a great engine to use for any local analysis — replacing what you might do with Pandas.
When you have a set of input files, some transformations to create intermediate files, and some clean and tidy output files, it’s probably a good time to use a database!
Mehdi Ouazza articulated this well in one of his LinkedIn posts (whose image is taken from Max Gabrielsson’s talk at GeoPython):
But the natural question is: if you pull your transformation logic into separate SQL files, how do easily run them in order?
Answer: there are several open-source SQL orchestrators available, such as:
- dbt-core, using the dbt-duckdb adapter (docs)
- SQLMesh, which is a strong contender to dbt (docs)
- yato, the world’s smallest DuckDB orchestrator (docs)
In fact, this type of DuckDB use case is one of the main reasons the creators built it!
DuckDB use case 4️⃣: Data format parser
If SQL isn’t your main language, you can still reap the benefits of DuckDB provided there’s a client for your language.
For example, it’s fairly common to manipulate Parquet files as part of a data pipeline written with Python. Historically, you’d need to install PyArrow for Parquet support, which is not a trivial dependency to add to your project.
The Python DuckDB client, however, has no dependencies (just Python 3.9 or newer!) so it’s very easy to add to a Python project. The function below is a simple example of how DuckDB can be used inside Python to copy data in any format readable by DuckDB into a Parquet file.
def to_parquet(file: pathlib.Path, compression: str = "zstd"):
"""
Copy the file to a Parquet file.
"""
file_parquet = file.with_suffix(".parquet")
duckdb.sql(
f"""
copy (from '{file.absolute()}')
to '{file_parquet.absolute()}' (
format parquet,
compression '{compression}'
)
"""
)
DuckDB use case 5️⃣: Data warehouse (MotherDuck)
Although it’s not one of the intended DuckDB use cases, you can use it as a data warehouse.
MotherDuck is a separate company to DuckDB Labs (the creators of DuckDB), and their product — also called MotherDuck — is a managed DuckDB service. Despite being a separate product to DuckDB, DuckDB has first-class support for interacting with MotherDuck instances of DuckDB, making it extremely easy to work in the cloud.
MotherDuck also has an extremely generous free tier, making it perfect for individuals and small businesses who are after a managed RDBMS without much hassle or overhead costs.
Just be aware of your security and governance requirements before signing your company up!
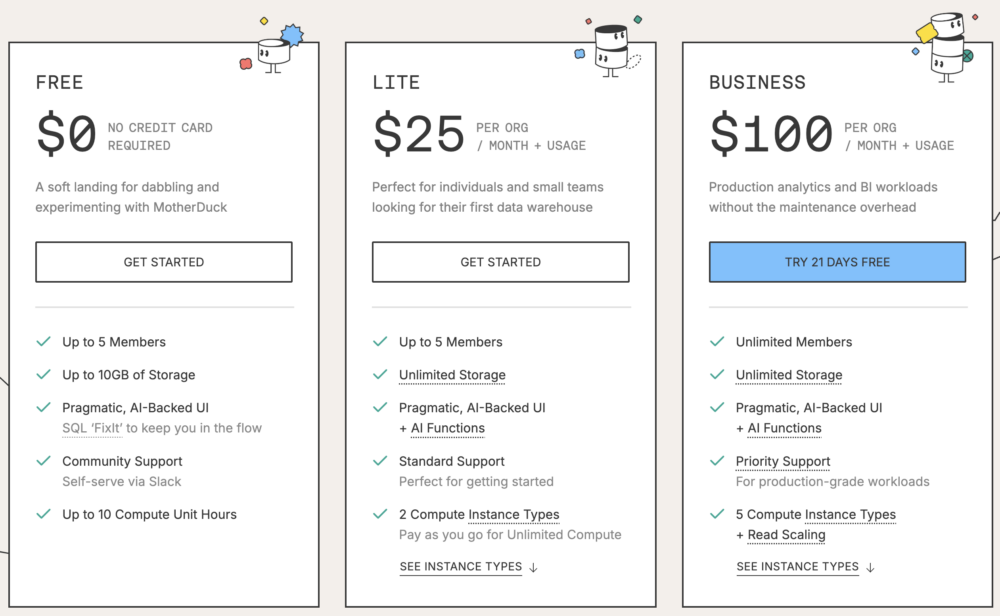
Source: https://motherduck.com/product/pricing/
DuckDB use case 6️⃣: Multi-engine data stack
Tools like SQLMesh are starting to support a “multi-engine” approach, which takes the idea of separating storage and compute to another level.
In a multi-engine approach, you could use one database technology for your computation, and another for your storage. Since DuckDB is free and open-source, using it for computation is a method for reducing costs — as well as potentially improving performance, depending on the alternative engines available.
The SQLMesh docs illustrate how you could use SQLMesh to store your data in a PostgreSQL database, but use DuckDB to transform data from an S3 bucket before inserting it into PostgreSQL:
There are also some great articles from Julien Hurault describing how to implement a multi-engine data stack:
- Julien Hurault – Multi-engine data stack – v0
- Julien Hurault – Multi-engine data stack v1
- Julien Hurault – SQLMesh & Multi-engine Data Stack
- Julien Hurault – Multi-engine stacks deserves to be first class
DuckDB use case 7️⃣: Cross-data-source queries
The first two examples above described that we can use DuckDB to query local files directly. DuckDB can also read some other RDBMS systems, as well as remote URLs over HTTP(S).
DuckDB isn’t limited to reading from a single source per query: we can query multiple data sources in a single query, and DuckDB will read from each of them at run time — meaning that DuckDB is always operating on the freshest data available.
Since DuckDB doesn’t need a server to run, this makes DuckDB an ideal engine for in-process transformation and is perfect for anyone comfortable talking SQL.
You can see an example (illustration only) of a DuckDB query which queries multiple data sources at the same time at:
DuckDB use case 8️⃣: SQL-first lakehouse (DuckLake)
2024 was an important year for data lakes and cloud data platforms:
- Databricks acquired Tabular and released support for Delta Lake tables
- Snowflake released support for Iceberg tables (Polaris) shortly after
DuckDB can read from both Delta Lake and Iceberg tables, but in early 2025, DuckDB Labs released DuckLake as an alternative data lake format aimed to make data lake catalogue management easier.
The DuckLake extension is available as part of DuckDB, giving you full data lake support at no extra cost, and without needing any additional infrastructure.
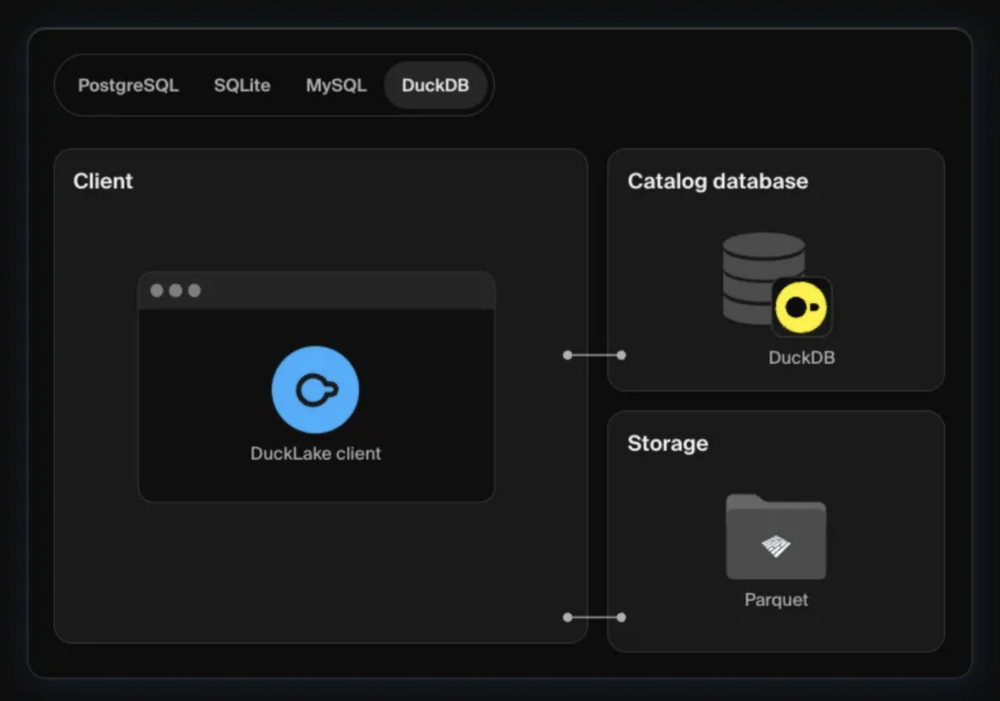
Source: https://ducklake.select/
DuckDB is an essential part of the modern data toolkit
DuckDB isn’t just a database: it’s a transformation engine that quacks SQL.
These DuckDB use cases represent just a fraction of its capabilities: it fits into the modern data toolkit seamlessly and has countless other applications. There are already loads of tools now powered by DuckDB; many can be found in the list linked below:
Whether you’re exploring DuckDB use cases for local analysis or enterprise applications, get in touch via the form below and we can have a chat about how Tasman can help enrich your platform with DuckDB!